

EmbeddedLLM @EmbeddedLLM
Your open-source AI ally. We are committed to making production-grade AI inference as accessible and reliable as electricity, powered by vLLM. Joined October 2023-
Tweets536
-
Followers1K
-
Following1K
-
Likes701

🎉 Unlimited-OCR from @Baidu_Inc now runs in vLLM. One-shot parsing of entire books with constant KV cache, powered by Reference Sliding Window Attention (R-SWA). 🧠 R-SWA keeps KV cache fixed throughout decoding — no memory blowup, no slowdown, no matter how long the output gets. 📄 Transcribe 40+ pages in a single forward pass under a 32K context budget, with remarkably low edit distance even at scale. 🪶 35% faster than DeepSeek-OCR at 6K output tokens, with fully constant TPS and GPU memory. 🔗 Recipe: recipes.vllm.ai/baidu/Unlimite… 🤗 Weights: huggingface.co/baidu/Unlimite… 🙏 Thanks to the @BaiduAI_News team for the collaboration.

🎉 Congrats to @poolsideai on Laguna M.1, a new open-weights agentic coding model. Day-0 support landed in vLLM v0.21.0. 🧠 70-layer sparse MoE: 225B total params, 23B active per token, 256K context 🔀 256 experts with top-k=16 routing, built for long-horizon agentic coding 🛠️ Native interleaved reasoning between tool calls, toggleable per request, Apache 2.0 Recipe 🔗 recipes.vllm.ai/poolside/Lagun…


Today we’re releasing the weights for Laguna M.1, our most capable model to date, with a 256K context length. Both base and post-trained checkpoints are now available on Hugging Face under Apache 2.0.

Your coding agent can run on open models you host yourself, not just a hosted API. vLLM serves them fast and cost-efficiently on your own GPUs, with broad hardware support across @NVIDIA, @AMD, and more. It speaks the same OpenAI Responses API that Codex uses, so any compatible agent points right at your server and any tool-calling model is a drop-in replacement. Spin up the latest GLM 5.2 (@Zai_org), Kimi K2.7 Code (@Kimi_Moonshot), or MiniMax M3 (@MiniMax_AI) model, or whatever open model fits your needs, and start coding. 🚀 Guide 🔗 docs.vllm.ai/en/latest/serv… Serving Recipe: recipes.vllm.ai

Reminder that you can use the Codex App, CLI and SDK with any open source model, not just with OpenAI models. developers.openai.com/codex/config-a…
Thanks for the kind words! Day 0 @MiniMax_AI M3 support came together thanks to this collaboration in the open. Big kudos to @rogerw0108 and @mgoin_ for the ongoing push, review, and mentorship. More improvements landing soon. 🙌 vllm.ai/blog/2026-06-1…

Great work to @vllm_project team and @nvidia on smooth, out-of-the-box day 0 @MiniMax_AI M3 experience with @inferact EAGLE3 spec decode. Here are the details of ongoing M3 workstream: NVIDIA, Inferact and SemiAnalysis are working hard on enabling disaggregated inferencing (PR
Great write-up from the @anyscalecompute team on PD disaggregation with Ray Serve + vLLM! PD Disagg is one of the most difficult techniques to get right in serving; the wins are real, but only in the right settings. Great to see it pressure-tested on AMD MI325X with Ray Serve + vLLM!

One pattern we keep seeing with customers serving LLMs at scale: Prefill-decode disaggregation is often treated like a magic wand. But the reality is more nuanced. So we wrote down the core insights for when PD helps, when it does not, and validated them on AMD + vLLM — where

vLLM v0.23.0 is out! 408 commits from 200 contributors (63 new). 🎉 Highlights: DeepSeek-V4 matures across backends (TRTLLM-gen attention kernel, sparse MLA decoupled from V3.2, EPLB for the Mega-MoE), Model Runner V2 now default for Llama + Mistral dense models, Gemma 4 Unified (encoder-free) + MTP, a maturing Rust frontend, multi-tier KV cache offloading with an object-store tier, and a unified reasoning + tool-call parser. Thread 👇

Singapore has come a long way. 🇸🇬 From AI adoption to AI infrastructure, the local ecosystem is now contributing to the layers production AI depends on: @PyTorch, @vllm_project, inference, sovereign AI, and open-source infra. Proud to see @RedHat_AI, @inferact, and @EmbeddedLLM building alongside APAC AI community.

The inaugural PyTorch Meetup Singapore brought together engineers, researchers, and community builders to talk about everything from vLLM project updates to the broader question of sovereign intelligence. Read the full technical recap and find presentation slides in our latest





Incredible collaboration from the team! Beyond basic inference support, we also have day-0 speculator and RL support🔥
🎉 Congrats to @MiniMax_AI on releasing MiniMax M3! Frontier coding and agentic capabilities, native image and video input, computer use, and a 1M-token context window, all in a single open model. At the heart of M3 is MSA, a new sparse attention architecture: instead of
🎉 Congrats to @MiniMax_AI on releasing MiniMax M3! Frontier coding and agentic capabilities, native image and video input, computer use, and a 1M-token context window, all in a single open model. At the heart of M3 is MSA, a new sparse attention architecture: instead of attending densely over the full KV cache, each query scores 128-token KV blocks and runs attention only over the top blocks. That is what makes 1M-token context practical to serve. M3 runs in vLLM with day-0 support, verified on NVIDIA and AMD hardware: ✨ MSA sparse attention with dedicated prefill and decode kernels ✨ 1M-token context serving with prefix caching and chunked prefill ✨ BF16 and MXFP8 checkpoints, with MoE backends for both Hopper and Blackwell ✨ Native multimodal input (image + video) ✨ Tool calling, reasoning parsing, and thinking-mode control for agent workloads Day-0 support like this is a true team effort. Grateful to the teams at @MiniMax_AI, @NVIDIAAI, @AIatAMD, and @inferact, and to the vLLM community for making it happen. 🙏 Deep dive into the implementation, kernel work, and deployment recipes: 🔗 vllm.ai/blog/2026-06-1…

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters Weights: huggingface.co/MiniMaxAI/Mini… MiniMax Sparse Attention: huggingface.co/papers/2606.13…

vime is a reference implementation for one reason only: make @vllm_project the best rollout engine for RL. This helps us better optimize vLLM for the whole ecosystem like @NovaSkyAI SkyRL, @PrimeIntellect Prime-RL, @nvidia NeMo-RL, @verl_project, and more! A wise man in leather jacket said: "We don't build PowerPoint slides and ship the chips. We build a whole data center. And until we get the whole data center built up, how do you know the software works? how do you know your fabric works?" - @NoPriorsPod
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem. Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Congrats to @GoogleDeepMind on DiffusionGemma 🎉 A 26B diffusion language model on the Gemma4 backbone, and the first dLLM natively supported in vLLM. It denoises 256-token blocks in parallel instead of generating one token at a time: 1200+ output tok/s at batch size 1 on a single H200 (FP8). Built on model runner v2's ModelState plus the existing speculative decoding path, with minimal scheduler or runner changes. FP8 and NVFP4 checkpoints are on the @RedHat_AI hub. Thanks to the @GoogleDeepMind, @RedHat_AI, and @NVIDIAAI teams! 🔗 vllm.ai/blog/2026-06-1…

Meet DiffusionGemma! An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license. Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem. Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem. Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others. More choice. More interoperability. More innovation. Learn more: vllm.ai/blog/2026-06-0… #LLM #RLHF #PostTraining #vLLM
🎉 Meet vLLM-Omni v0.22.0, a major upgrade for omnimodal world models and production-grade multimodal serving. 🌍 Day-0 @NVIDIAAI Cosmos 3 world models: text, image, audio, video, and action, in and out. 🤖 Robot serving: DreamZero + OpenPI realtime API. 🎙️ Production TTS: Qwen3-TTS, Qwen3-Omni, VoxCPM2 and more. 🎨 Faster image/video/diffusion: Wan 2.2, HunyuanVideo 1.5, LTX-2.3. ⚡ Broader quantization (FP8/INT8, MXFP4/MXFP8, W4A16, ModelOpt) and hardware coverage. 339 commits, 124 contributors, 52 of them new. Thank you all. 🙌 🔗 github.com/vllm-project/v…
🎉 The vLLM community just got a free course, built by @RedHat_AI with @DeepLearningAI. It walks through the full optimize → deploy → benchmark lifecycle for serving open models. Three labs, each on a live vLLM server: - Compress: quantize a Qwen model with LLM Compressor, then measure the size vs. accuracy tradeoff - Serve: deploy with vLLM's OpenAI-compatible API and watch continuous batching, PagedAttention, and prefix caching in the live metrics - Benchmark: simulate traffic with GuideLLM and check quality with lm-eval A lot of the work went into visualizing what actually happens under inference, thanks to @cedricclyburn: how tokens flow through the model, how the KV cache grows in GPU memory, and what changes when you move from FP16 to INT8/INT4. ~1.5 hours, 9 lessons, 3 labs. Free on DeepLearning.AI. 📝 Read more: vllm.ai/blog/2026-06-0…

New short course: Fast & Efficient LLM Inference with vLLM, built in partnership with @RedHat and taught by @cedricclyburn. Learn to quantize an open-source LLM, serve it with vLLM, and benchmark your deployment across speed, cost, and accuracy. Free to enroll:
Amazing work! More and more RL frameworks are using vLLM as default. @vllm_project along with @anyscalecompute and @NovaSkyAI revamped weight syncing and improved wide-ep deployment for rollout!

Excited to share some of our work on improving vLLM for RL! A number of RL frameworks, including SkyRL, use vLLM for inference, and we’ve noticed some common problems: 1. Weight syncing between training and inference is implemented in an ad-hoc fashion and duplicated across
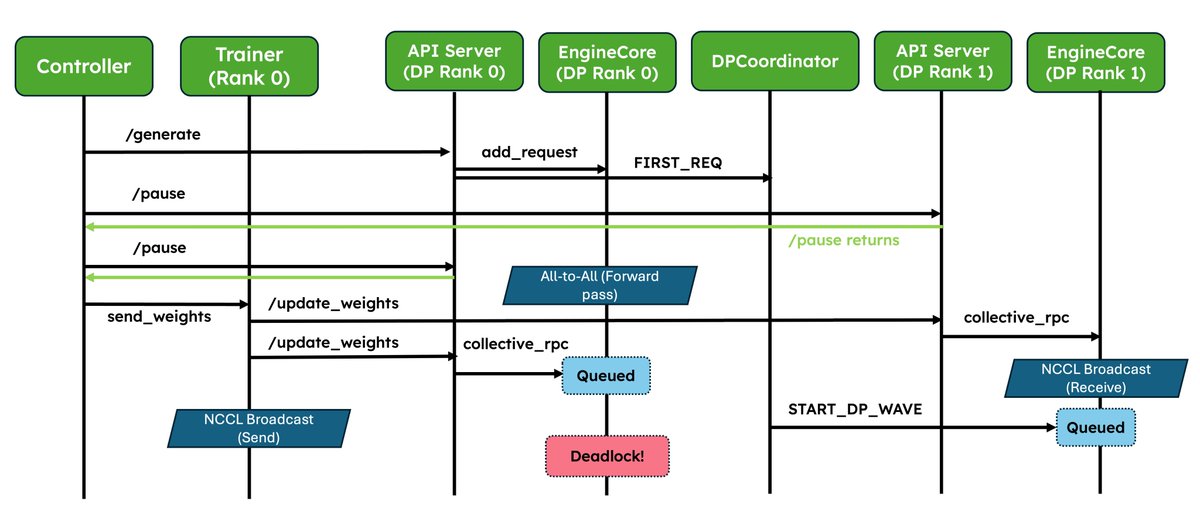
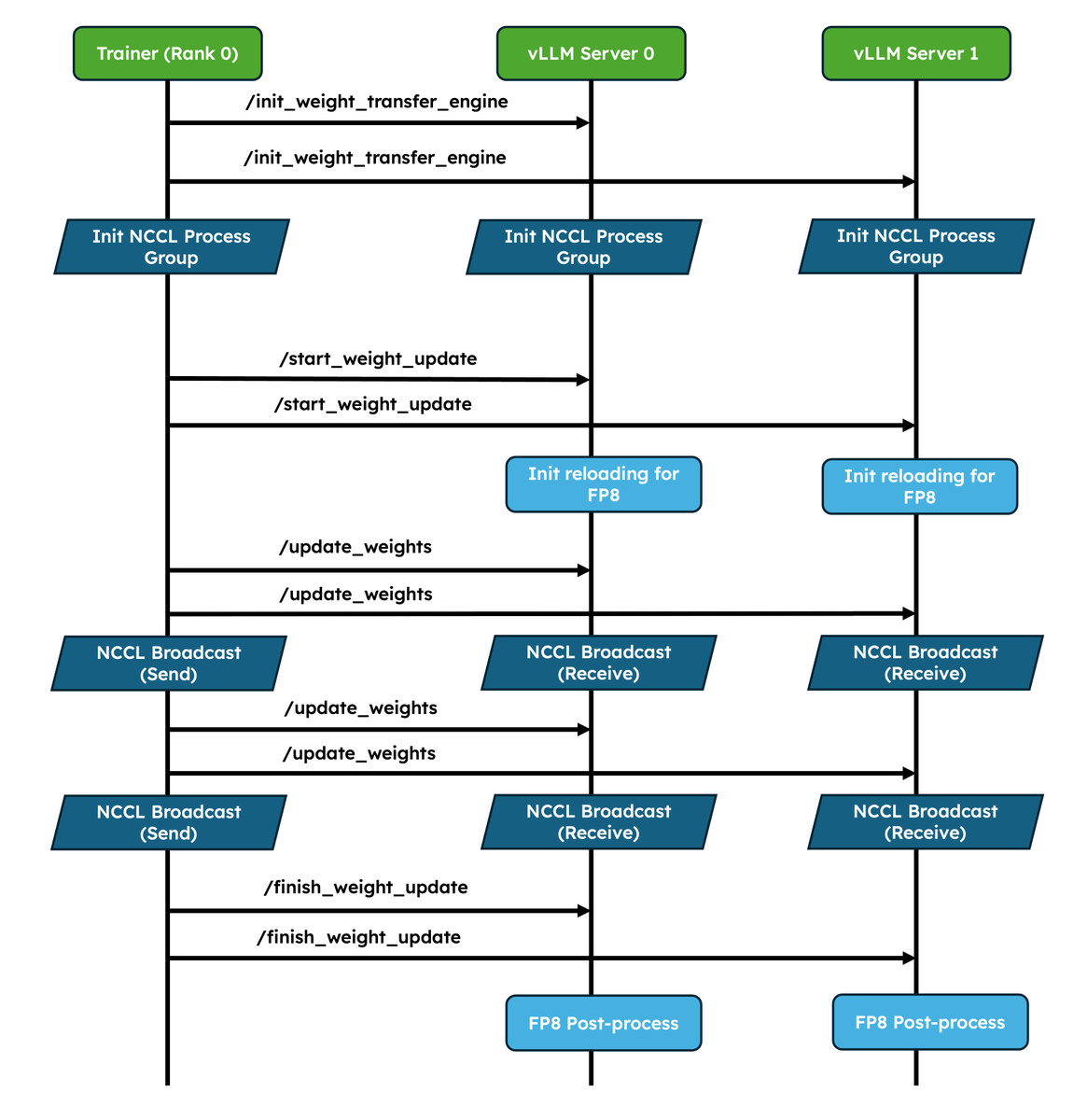
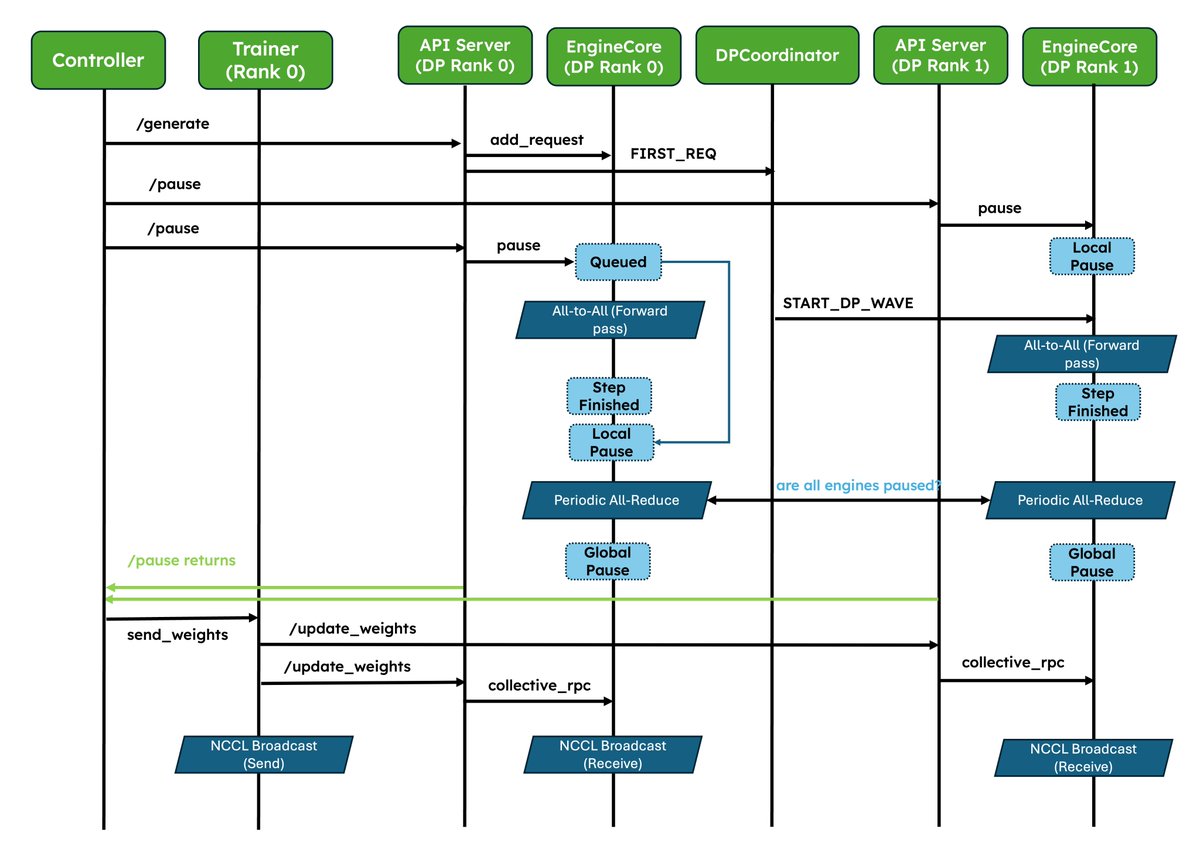
We've shipped two major upgrades for RL✨! 1. Native weight syncing APIs: Standardizes weight transfer, provides optimized implementations for NCCL and CUDA IPC out of the box, and also lets frameworks easily bring their own. 2. Improved pause/resume for Async RL: Careful coordination between DP ranks so that engines don’t deadlock. Validated at scale in P/D, wide-EP setups! In collaboration with @anyscalecompute, @NovaSkyAI, and @RedHat. More and more RL frameworks are using vLLM as the default for inference, details in the blog 👇 vllm.ai/blog/2026-05-2…
🦀 rustifying vLLM, one part at a time, great work @BugenZhao!
🦀 The Rust frontend is officially merged into vLLM! As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1. Early



🦀 The Rust frontend is officially merged into vLLM! As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1. Early numbers: on a preprocess-heavy workload, ~837 req/s vs ~162 req/s for default Python — ~5x in a single process. A few design choices we're excited about: • Layered crates with clear boundaries • Stream-native pipeline — non-streaming for free • Builds on stable Rust Huge thanks to @BugenZhao from @inferact for introducing the work at @PyTorch Meetup Singapore. github.com/vllm-project/v…

Great cohosting this luncheon with @a16z and Mirendil at MLSys 2026 yesterday! 🙌 We brought together top researchers and AI systems engineers for an afternoon of rich conversations on @vllm_project, the frontier of inference, and where AI systems are headed next. Huge thanks to everyone who joined — the energy in the room was something else. This is exactly the kind of cross-pollination between labs, infra teams, and industry that pushes the whole stack forward. More to come. 👀 #MLSys2026 #vLLM

Mary Newhauser @m_newhaus
108 Followers 967 Following @FastinoAI | small models | local ai | open source | super gpu poor atm
0xAHD @ahd_1337
155 Followers 1K Following RetaaardMaxxing Ex 0xCoinshift | Ex @CRED_club | Ex Billdesk | Ex Start Global 1x Founder | Hacker Running around in SF learning LLMs now.

Vimal Manivannan @vimalyohen
298 Followers 5K Following Verification Engineer #semicon-professional.
Ioannis Koltsidas @ikolt
218 Followers 537 Following Flipping bits @Axelera.ai. Previously @Google, IBM Research. Opinions subject to change in light of new information 🤷🏻♂️
kolade @akoladefaj
87 Followers 414 Following Backend & AI Engineer. Distributed systems, reliability & AI infrastructure.



L4L4-K @L4L4_K_181
6 Followers 434 Following Tokyo-based Software Engineer focused on AI integration, data workflows, performance software, and computer vision. Python, C++, CUDA.
Darius Tan @dariustan_
32 Followers 172 Following
autodidac @autodidaclzfm
1 Followers 5K Following
Matthew Gordon @46emma538
13 Followers 331 Following
Yuma Ichikawa @yuma_1_or
3K Followers 169 Following Fujitsu (Senior Research Manager), RIKEN AIP, Ph.D. (Univ. Tokyo), The one in the articles? Just a lookalike. I’m actually just doing Gaussian integrals😎
Tang Yanfeng @TangYanfeng
12 Followers 409 Following
Towards a Philosophy ... @goatsintheshell
55 Followers 915 Following
m ahu @mahujam
5 Followers 396 Following
しんちろ @sinchir0
2K Followers 1K Following 一つのことをやりきる / 機械学習エンジニア / Kaggle 2x(Competitions, Notebooks) Master / 共著に「Kaggleではじめる大規模言語モデル入門」「Polarsとpandasで学ぶ データ処理アイデアレシピ55」/ マラソン サブ5.5

FlagOS Community @FlagOS_Official
350 Followers 366 Following An open-source system software stack for AI. Bridging Model–System–Chip layers. Build once, run across diverse hardware.

さるもく|製造... @sarumokueito
77 Followers 294 Following 製造業の受注処理まわりをPythonで半自動化しています。 ノンプログラマーですが、OCR / pandas / Excel自動化 / tkinter を試行中。 現場の手間とミスを減らす改善が好きです。
~JoyCode @AgoroJocelyn
34 Followers 522 Following Passionné de data, amoureux de la science.C/C++,SQL,Python,Django,VueJs, Ionic, ImbaJs😍. Définitivement tombé amoureux de JavaScript❤️
Or Perlman @OruP46
17 Followers 247 Following CTO of https://t.co/IjW3YtIyZk|AI chat & voice for websites|19 yrs shipping code|Tokyo|Father of one|On software craft, AI, and the tech I can't stop reading about
bing @bing29759125
1 Followers 135 Following

シオン@大学用�... @shion1010777
36 Followers 58 Following 18/Male/HOSEI GIS/Table tennis/Ikimonogakari/Comedy/Follow me
Anonymous_joker @anonymo_joker
34 Followers 2K Following
万千 @wanqian_nilk
7 Followers 745 Following
Name Cannot be Blank @modomains
345 Followers 4K Following
SYUN@笑う門には�... @syun88AI
2K Followers 7K Following 27歳の台湾人、AI,ROBOTICS,CV*投稿感想や呟きは、関わってきた組織や会社とは一切関係ありません。 自己紹介https://t.co/peGTZFCcJf
Dd @Ddzfjt
4 Followers 70 Following
Mohamed Zayed @MoZayed007
215 Followers 3K Following Research Engineer @ https://t.co/Jh1x5Gh89z On my journey of 10K hrs, Opinions are my own.
mauryaland @mopodono
83 Followers 2K Following


Gary Oikawa @GaryOikawa
577 Followers 3K Following
Kangying L.(Connie) @timcanby
295 Followers 2K Following kaonavi ←SB Intuitions←https://t.co/m94NkbccQb←RecursiveAI(joined pj: https://t.co/CyM5PgT2Pn) ←JSPS DC2(図書館情報学&DH)Ritsumei| Women in Tech🙌 Build in Public💪
Hikari∣LocalLLM⚡ @Hikari_07_jp
3K Followers 900 Following 2× RTX PRO 6000 + TR Pro 9965WX | Daily local LLM experiments on real silicon. RepE tuning • vLLM • quantization. Building intelligence I actually own.

じんや @kusojin_nisei
20 Followers 188 Following

Rafique Shaik @shaiktweetss
413 Followers 4K Following TPM at Google Japan|| Im lost on a quest for an utopian peace. 人生はダイジョウブじゃない #teampixel
subabusucu @subabusucu
0 Followers 119 Following





tianhang zhu @TianhangZhuzth
38K Followers 28 Following head of LLM training at @Fundamental. I led RL in the early days at @Alibaba_Qwen and 01ai.
cedric @cedric_chee
3K Followers 501 Following SWE | @fastdotai alumni, independent researcher, tester | ex-entrepreneur @AntlerGlobal | GitHub: cedrickchee | scaling verification and evaluation
LightSeek Foundation @lightseekorg
2K Followers 1 Following Creator of TokenSpeed, TorchSpec, and SMG — building next-generation AI infra systems.
波妞PONYO @ponyodong
12K Followers 715 Following AIGC Video Creator & Animation IP Strategist 🐷 前 Peppa Pig China Mktg. 🎨 专注 AI 视觉叙事与漫画 IP 孵化 💡 分享高阶 Prompt 与工作流实战 商业咨询PONYODONG

Jackmin @jackminong
2K Followers 951 Following On a little excursion. Waku Waku! On sabbatical @PrimeIntellect 🇺🇸 Previously @JinaAI_ 🇩🇪 @MoneyLion 🇲🇾
serein @you1873118
14K Followers 7K Following I hope tomorrow will be better! Bluebird Club Just here for the memes Sharing everything fun
SeeInX (AI Art) @seeinx_aiart
12K Followers 2K Following AI Art | ComfyUI | Realistic Style I still have so much more I want to show you..

Sigrid Jin 🌈🙏 @realsigridjin
15K Followers 1K Following experiencing context rot @ubc 🇨🇦 🇰🇷 proudly korean-canadian

Vigo Zhao @VigoCreativeAI
8K Followers 392 Following Designer × AI Engineer | Ambassador @Alibaba_Qwen | Cut e-commerce AI costs ~60%|Reverse-engineering prompts from a single image
GENEL | AIを用い�... @genel_ai
18K Followers 182 Following MO3IC所属|AIを用いた動画制作|企業研修も| 検証: 画像生成AI / 動画生成AI / 音声生成AI| ゼロからAIでCMや動画が作れる解説はnoteで📒 Kling AI Creative Partner
ミロ @ml0_1337
4K Followers 341 Following AIドパガキ。大学中退の高卒→受託事業→AI SaaS開発・運営、外部CTO/技術顧問。技術顧問等の相談はDMからお願いします。
TonoKen3🤖Local-LLM... @Tono_Ken3
3K Followers 1K Following Founder/CEO of Lna-Lab K.K. Former publishing exec building local LLMs, AI agents & Physical AI for human-AI coexistence with RTX PROs (SM120).Civilization OS🤖
からあげ @karaage0703
30K Followers 2K Following エンジニア/AIのお仕事してます/からあげ大好き/はてなブログ書いてます/色々作ってます/からあげは概念/Amazonのアソシエイトとして適格販売により収入を得ています
株式会社フィッ... @Fixstars_JP
5K Followers 524 Following フィックスターズ公式アカウント。 「Speed up your AI」をスローガンに、優秀なエンジニア達がお客様のAI活用とAI開発を加速しています。グループ全体の最新情報をお届けします。 【東証プライム:3687】米国でのビジネスはこちら → @Fixstars_US
ハカセ アイ(Ai-H... @ai_hakase_
15K Followers 825 Following 生成AIと猫への愛50%ずつで構成されています、葉加瀬あいです🐾 🧠クリエイター向けAI解説:YouTube、Note、X 🤖AIエージェント開発:自社、受託 などを行う、小さな会社を経営しております。 PC周り、ジム、ゴルフ場が最近の住処です😽✨ お役立ち投稿は「ハイライト」欄にまとめてます🥳
Hiroki Yamamoto @tereka114
4K Followers 814 Following Acroquest Technology Co., Ltd/Data Scientist/Kaggle Grandmaster/CV/SA/C++/Python/Kaggle https://t.co/ANLAF8Pq7K お仕事などのご依頼、ご相談はDMorMLにてご連絡ください。
Yuma Ichikawa @yuma_1_or
3K Followers 169 Following Fujitsu (Senior Research Manager), RIKEN AIP, Ph.D. (Univ. Tokyo), The one in the articles? Just a lookalike. I’m actually just doing Gaussian integrals😎
Qubitium @qubitium
1K Followers 4K Following Building GPT-QModel, ModelCloudAI. Contributor to stuff you are probably using.
Chew Kok Wah @chewkokwah
31 Followers 1K Following Make the world a better place 创造美好新世界 Wujudkan dunia baru yang lebih indah

Robert Shriver Barnes @sailorbob74133
84 Followers 57 Following The righteous will rejoice when he sees the vengeance; he will bathe his feet in the blood of the wicked. Yonah Cp. 4: should not I have pity on Nineveh...?
Kalyan @nkalyanv99
67 Followers 110 Following 1st year PhD Student @TU_Muenchen. On a random walk through the subfields of ML.
Enrique Guerra 🇺�... @EnriqueGuerraF
167 Followers 2K Following PhD in ML @MonashUni - Libertarian, e/acc.
~JoyCode @AgoroJocelyn
34 Followers 522 Following Passionné de data, amoureux de la science.C/C++,SQL,Python,Django,VueJs, Ionic, ImbaJs😍. Définitivement tombé amoureux de JavaScript❤️
Ally @treasureh8nter
2K Followers 529 Following 🌏 UK-Taiwan | Ex-Tokyo Banking (16yrs) 💹 AMD & AI Investor 🚀 XRP Enthusiast 🔎 Visual Data & Market Insights 👇 “Follow” for cutting-edge tech & finance!
Terry_ray @Terryra00832493
31 Followers 117 Following Student life: No steady income yet, just dipping into fund investments. Tech junkie devouring industry articles daily.
Hamid Shojanazeri @Nazeri2010
390 Followers 932 Following ml @pytorch model optimization, distributed training.
Graver256 @Graver256
26 Followers 271 Following

Amil Agrawal @amilabsolute
25 Followers 840 Following ml research intern @snap | cs + math @brownu | prev inference @amd, robots @raytheon | 20
Anmol soin @anmol_soin
151 Followers 889 Following Not much into tweet ;) I better do insta - @anmol_amo ✌️ Peace out.
Sourav Chakraborty @souravzzz
61 Followers 456 Following
Doplano @_doplano_
97 Followers 4K Following
Wes Henderson @wesjh_
101 Followers 356 Following Focused on Enterprise AI @ AMD |Former IP Lawyer | Current AI strategist | Too many hobbies and interests to count. UMSL BioChem| @SLULaw | @UTAustin AI/ML
deadend890 @deadend672
2 Followers 2 Following
Sam Luu @TheRea10G
8 Followers 50 Following
DanNeo S.S. ✮ 𓂃�... @DanNEO_SS
2K Followers 2K Following Wordsmith | Indie | Creator of #DarkNeology | Christian sci-fi & experimental fiction | Words that hit different. Books on Amazon + wild thoughts on Substack.
Razine Moundir Ghoarb @RazineMG
86 Followers 1K Following atoms to abstractions, one token at a time.

Nolan @Nolan1831749
7 Followers 24 Following
vatsal choksi @vatsalchoksi7
17 Followers 66 Following
Stephan90 @Stephan9015
607 Followers 190 Following
aCE @AlybiSaCE
3K Followers 3K Following Talent Agent @ProxyTalent | [email protected] | Representing the best @EpikWhale @anonzr @Crylix @fnmoneymaker @regsita & more
Davit Khachatryan @DavitKhachatry
48 Followers 177 FollowingYou might like



















