

Applied Compute @appliedcompute
The Best AI is Built Not Bought appliedcompute.com San Francisco Joined July 2012-
Tweets191
-
Followers5K
-
Following18
-
Likes352
“A modelless company is sitting on shifting sand.” Our CEO @ypatil125 sat down with @mariogabriele to talk about why owning your model is the difference between building on bedrock vs on someone else’s roadmap. It’s the core of what we do at Applied Compute. We train better, faster, cheaper custom models on your data, serve them in production, and continuously improve them as your definition of “good” evolves. Your model becomes your moat instead of a dependency that can change underneath you. Full conversation below!

"A modelless company is sitting on shifting sand." Yash Patil (@ypatil125) is the founder and CEO of @appliedcompute, a company that trains custom models on company data and serves them in production. His conviction: every organization has its own definition of what good looks

Harvey partnered with @appliedcompute to train a legal agent. We optimized each part of the agent stack: - eval loop - agent harness and compaction - post-trained GLM-5.1 using reward signal from our Legal Agent Benchmark (LAB) More in our agent-training deep dive:


Harvey partnered with @appliedcompute to train a legal agent. We optimized each part of the agent stack, including the eval loop, agent harness and compaction, and post-trained the underlying GLM-5.1 model using reward signal from Harvey's Legal Agent Benchmark (LAB). Check out more in the agent-training deep dive below. Kudos to @nikogrupen, @ItsJulioPereyra, @rhythmrg, @jacob_dphillips, and @raymondmfeng for leading this effort - more to come, with lots of opportunity to push the frontier with GLM-5.2.
It was great collaborating with @nikogrupen, @ItsJulioPereyra, and @gabepereyra on a custom post-trained model for LAB. The rigorous work Harvey is doing to map out and build representative evals that reflect how real legal work gets done will pay massive dividends over time and help them continue to build unique research and model IP.
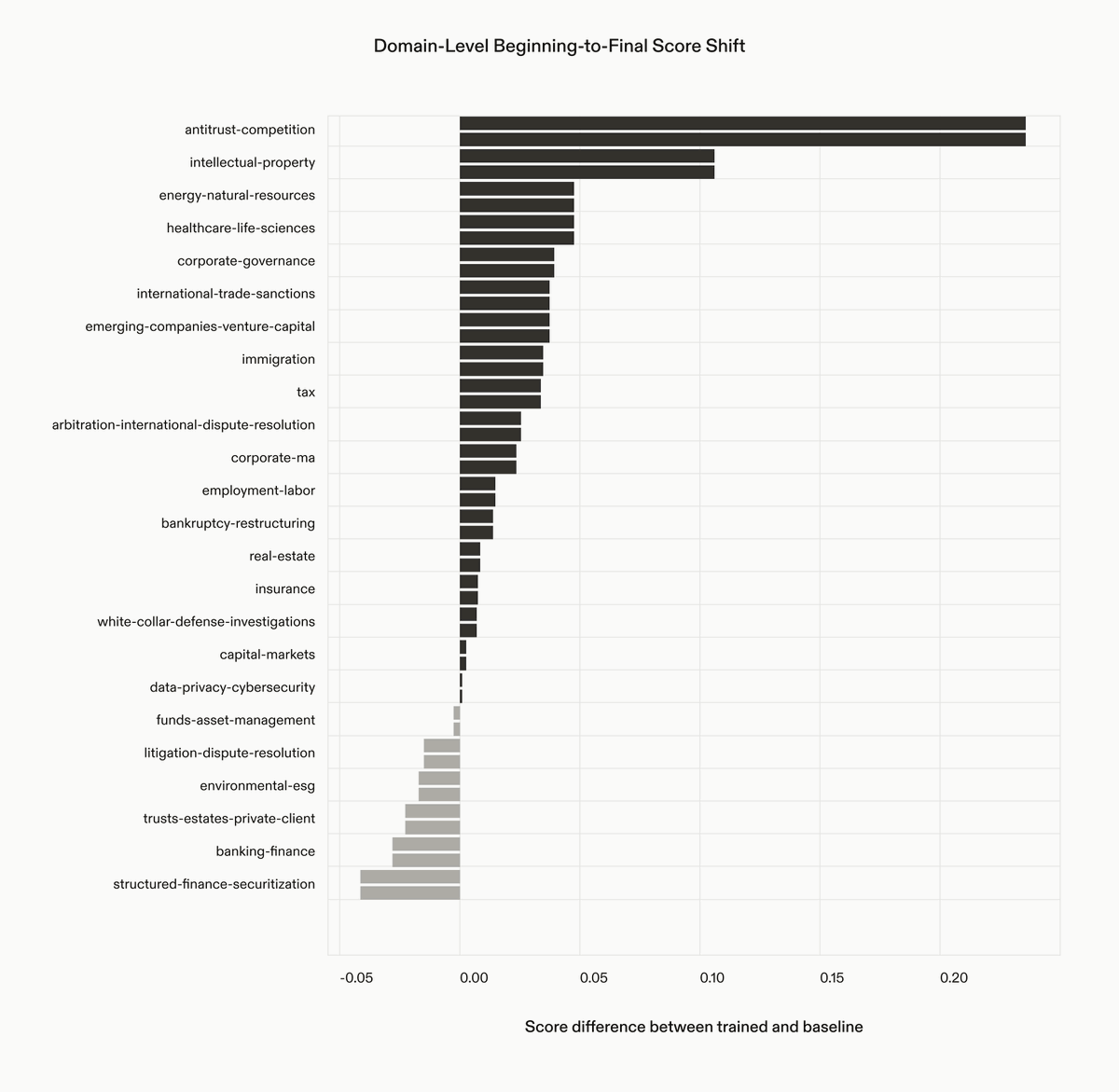
We partnered with @harvey to post-train the state-of-the-art legal agent on their LAB benchmark. It surpasses Opus 4.8 Max and GPT-5.5 xhigh.
More evidence that the frontier is attainable with (1) high quality environments and domain expertise, of which @harvey has in abundance; (2) post training infrastructure to execute big runs. This ran on our Blackwell cluster without any issues, thanks to infrastructure that allows us to elastically scale inference compute. Was great to collaborate with @gabepereyra @nikogrupen and team!
We partnered with @harvey to post-train the state-of-the-art legal agent on their LAB benchmark. It surpasses Opus 4.8 Max and GPT-5.5 xhigh.

If we’ve learned anything this past week it’s that GLM is a strong base for customization. Together with @appliedcompute, we focused on GLM-5.1 and have results that are a great example of what full-stack agent optimization looks like —> post-training + harness + verifier. Real potential to push the Fable frontier now with GLM 5.2. Great working with @ypatil125 @rhythmrg & team!
We partnered with @appliedcompute to train a legal agent. We optimized each part of the agent stack: - the evaluation loop - the agent harness - and post-trained the underlying GLM-5.1 model. The result? The agent achieved the highest rubric pass rate on our Legal Agent Benchmark (LAB) of any available model. Much more in our agent-training deep dive with @appliedcompute:


Read the full report: appliedcompute.com/case-studies/h…
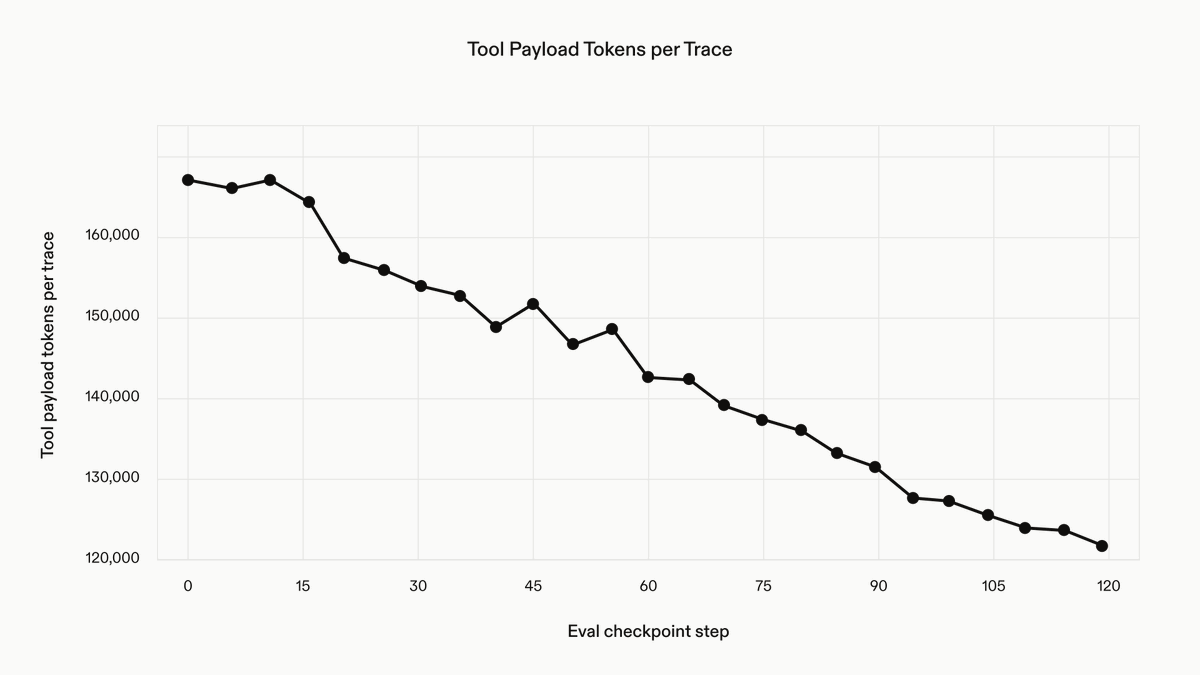
We rebuilt the agent harness to operate well in challenging long context environments. Legal source documents are huge, with the 90th-percentile LAB task carrying nearly 100k tokens and some exceeding 200k. We added compaction so the model summarizes its own transcript and continues past its context limit, letting it work far longer on a task without losing the thread.
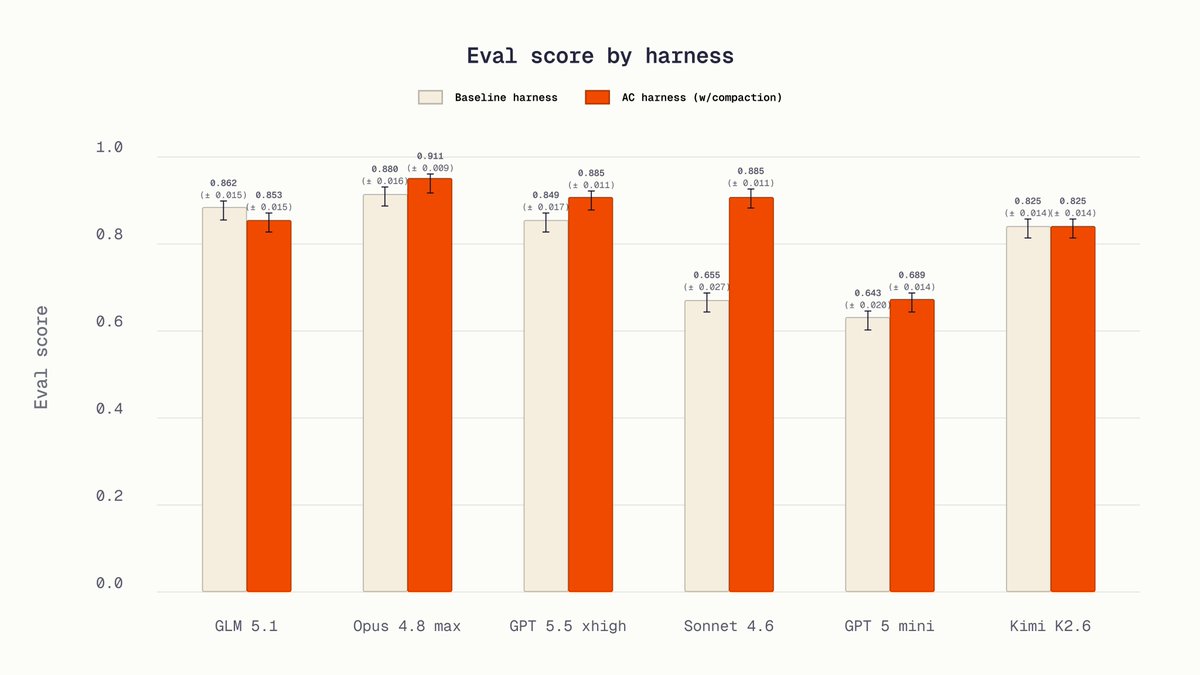
We partnered with @harvey to post-train the state-of-the-art legal agent on their LAB benchmark. It surpasses Opus 4.8 Max and GPT-5.5 xhigh.
Model strategy for @harvey: We are working on the first model in our legal foundation model series, inspired by @cursor_ai's Composer. Two goals: 1. Allow us to serve frontier intelligence across our product surface areas at an affordable price and a strong security posture. 2. Create the foundations for law firms to build their own specialized models and own their own intelligence. The model series will focus on complex client matters that span months and take dozens of associates. The agentic system will learn to control legal tech tools, sub agents and ask for help from frontier models or human partners, much like a senior associate. We’ve open sourced benchmarks for evaluating our initial post training work that represents work done by associates and in-house lawyers. We are scaling these significantly using synthetic and human pipelines as well as building private evals for firms. Open sourcing this data has allowed us to quickly validate the feasibility of post training open weight models for legal work. With our research partners we’ve already shown promising results post training open source models to approach frontier performance: 1. @baseten - novel compaction strategies for analyzing large data rooms. 2. @FireworksAI_HQ - matching frontier performance by using frontier as an advisor. 3. @appliedcompute - improving performance and reducing cost of large scale review tables. 4. @trajectorylabs & @nvidia - sovereign continual learning over client matters. We plan to continue to invest heavily in working with research partners and open sourcing our data, models and research as much as possible. We believe open research in legal will be important to building trust in the frontier ecosystem. We are also scaling our research team. Harvey Labs is our internal research group, responsible for pushing the frontier of legal intelligence and working closely with labs, research partners, and academia to bring the frontier of agent research into Harvey. Labs is run by @nikogrupen and @ItsJulioPereyra - Niko worked on multi-agent RL at Google Brain and Julio clerked and worked in BigLaw. We believe this pairing is crucial for building frontier legal AI systems. Together they have already made significant progress in scaling our data and training efforts. The long term goal of Harvey Labs is to contribute to the research and infrastructure required for the legal industry to create a frontier ecosystem. We believe that the best version of legal super intelligence is one where each law firm, enterprise and government owns their own specialized version. We are hiring for Harvey Labs across the post training, agent and data stack and open to acquiring talented teams / neolabs in this space. If interested please DM me.
Read the full research report: appliedcompute.com/research/conti…
The collapse also shows up in the answers themselves. Under various metrics of intra-prompt diversity, a policy trained with GRPO leads to less diverse responses than a trained with adaptive entropy control. Moreover, we observe that entropy allows response diversity to be tuned, where the optimal entropy target correlates with more response diversity.

Preserving entropy is critical for continued training; in modern post-training recipes, entropy is often a fixed resource that gets exhausted over the course of a training run, making it difficult for the model to improve and learn on new tasks. Adaptive entropy control methods expose entropy as a controllable hyperparameter instead of a side effect. We find that in a continued training setting, GRPO leads to entropy collapse which stalls training performance on subsequent training phases. REPO-R (Petrenko et al., 2026) can hold entropy near a specific target, preventing this collapse, and pushing performance higher in follow-on tasks when the target entropy value is properly tuned.

The workflows that make you different shouldn't run on the same general models everyone else rents. Our co-founder @rhythmrg on when to train your own.

Deepak Gupta @deepak21684
212 Followers 2K Following Loves all things tech | Loves investing/ trading in the equities
Abhilash @AbfrmBlr
61 Followers 1K Following
Ravi @tamilravi
25K Followers 8K Following Dravidian. I write mostly in Tamil about Politics in India/Tamil Nadu, Movies, Tech, and life.
Eric Xu (e/Mettā) @xleaps
35K Followers 4K Following polymath, polyglot, root of a ternary tree. building https://t.co/GTxh2wWMcX prev @Meta @Google @Reddit phd in classic ai; rookie pilot 🛩️; martial artist




Whoa @whoaboard
424 Followers 7K Following The whoa board makes things glow, it also makes glow-y things touch sensitive
Mike DOUDJE ABDALLAH @MikeAbdallah5
335 Followers 6K Following 💼 Salesforce Consultant | Tech Lead | Software engineer | Android Developer | IT Support
Ofer Razon @orazon
471 Followers 3K Following


Sabuhi A. @SAbbaszad70856
22 Followers 6K Following
ab @amirhossei57289
0 Followers 2K Following
Ahmed Fouzan @AhmedFouzan
68 Followers 1K Following Figuring out life one step at a time | Cat person | Data Platform @Outsystems | Previously @Uber, @Citrix
Ravindra Kumar @ravidsrk
87K Followers 19K Following
Fatih⏩⤴️ @taskinfatih
621 Followers 7K Following Lover of all novel and hard concepts: especially machine learning and systems theory
sakshi agarwal @sakshithought
20 Followers 872 Following

d I @dI1866304634055
230 Followers 6K Following
Florespacez @florespacez
194 Followers 2K Following
Aaron Levie @levie
2.9M Followers 815 Following ceo @box - your business lives in content. unleash it with AI
George Parker Jr @georgeparkerjr
1K Followers 5K Following AI strategy + LLM-assisted formal methods. Founder @genxcouch_ai and @@ADHDstackAI Pattern recognition across domains.

Pierfrancesco Beneven... @PierBeneventano
1K Followers 2K Following Postdoc at @MIT | ex PhD student @Princeton | Thinking of how to frame theoretically agents and using agents for theory research, while brewing my espresso.
W @nzkiwifruity
4 Followers 187 Following
nishil @nishil
2K Followers 1K Following following my curiosities | prev @chapterone @decentralisedco @biconomy
Feng Yao @fengyao1909
1K Followers 810 Following @thinkymachines | PhD-ing @UCSD_CSE Prev. @TsinghuaNLP @MSFTResearch @Amazon
RVA Movers @MoversRva
2K Followers 2K Following
Umer Shaheen @theumershaheen
3 Followers 136 Following
Sourav Bhar @souravbhar871
220 Followers 645 Following Building something new; previously at @microsoft, @mckinsey, @wharton
Hossein Sharifi N. �... @Hossein_SHN
670 Followers 2K Following Researcher @RBCBorealis | Ph.D. in Computer Science @SFU | Developing intelligent machines (I think!)| Ex: @VanProstateCtr, @pmcancercentre, @Novartis
Mikhail Radik @mikhailradik
15 Followers 131 Following Former Head of Product @mercor_ai (employee #8). Building what’s next in AI.

Aaron Wykoff @social_snippets
36 Followers 2K Following I help others in sales and marketing scale through AI and automation.
Akash Gupta @Akashgupta197
123 Followers 6K Following Fintech & Mortgages products, industry and trends
Anais Killian @anaiskkillian
457 Followers 569 Following @openai | @harvard cs + math, @kempnerInst https://t.co/DwggjDCQrh
Andrew Case @attrc
27K Followers 5K Following @Volatility Core developer, Dir. of Research @Volexity, @lsucyber, The Art Of Memory Forensics Co-Author
Brian @whoismarchb
4 Followers 261 Following postdoc @uofcalifornia · bug phd · ecology enthusiast · currently in an AI rabbit hole for some reason
Dominic Waltz @dpwaltz_
16 Followers 625 Following Curious builder exploring AI systems and product, grounded in institutional finance
Yash Shah @YashSha48797747
10 Followers 278 Following
Leo Shao @LeoShao_
20 Followers 275 Following Investing @kleinerperkins. Prev @TPG, @MorganStanley, @Harvard
Moyal @AxelMoyal
0 Followers 21 Following


Sigil Wen @0xSigil
53K Followers 7K Following thiel fellow | chairman @extraordinary 🇺🇸 | angel investor | @ConwayResearch Web 4.0: https://t.co/dskpyV1CqW


TBPN @tbpn
850K Followers 965 Following Technology's daily show returns 6/26. Hosted by @johncoogan & @jordihays. Streaming live 11a-2p PT every weekday. Sign up for our daily newsletter at https://t.co/Nhf5ohjayg.

Lulu Cheng Meservey @lulumeservey
139K Followers 3K Following Rostra founder, Shopify board, ex Activision & Substack, writing https://t.co/4xKo7wQTQo
Dylan Yu @dyu1729
33 Followers 302 Following
Sahar Zadeh @sahar__zadeh
688 Followers 595 Following 🚂ing @appliedcompute prev @insightpartners @natgeo @gatesfoundation & @harvard
Pranav Vaid @pranav_vd
41 Followers 57 Following
Ben Scharfstein @benscharfstein
2K Followers 2K Following building @appliedcompute. started a few companies. previously product @scale_ai, @google, applied math @harvard
Saquon Barkley @saquon
787K Followers 573 Following
Michael Chen @michaelzchen5
1K Followers 400 Following Building @appliedcompute // Prev. @Scale_AI, @Harvard
vinjai @vinj_ai
180 Followers 108 Following building @appliedcompute / previously AI @Watershed, math @Stanford

Brandon Snider @snider13_
249 Followers 633 Following Research Lead @appliedcompute | Prev. @Stanford

Jacob Phillips @jacob_dphillips
1K Followers 1K Following building @appliedcompute. prev American Dynamism @a16z, ML @scale_AI, CTO @Themis_AI, AI + History @MIT
Linden Li @lindensli
3K Followers 868 Following Co-Founder @appliedcompute. Previously scaling @OpenAI, @DbrxMosaicAI, @NVIDIA
Rhythm Garg @rhythmrg
4K Followers 479 Following Co-Founder, CTO @appliedcompute 🚂 prev: research @OpenAI @Stanford
Bryan Lee @_brylee10
145 Followers 252 Following daily 1%. building @appliedcompute. prev Sentinel (YC), @twosigma, @harvard
Yash Patil @ypatil125
9K Followers 612 Following Co-Founder, CEO @appliedcompute 🚂 prev: @OpenAI, @StanfordYou might like




