

-
Tweets329
-
Followers617
-
Following600
-
Likes3K

I'll be presenting 3 papers at ICML 2026🫡 h1 (Spotlight) trains models to reason over longer horizons using curriculum RL over composed short-horizon data. This allows models to generalize to harder tasks and improves performance even at high pass@k. LongCoT isolates and benchmarks long-horizon CoT capabilities, pushing models to reason over tens and hundreds of thousands of tokens in an output. Rubric Curriculum RL uses the generation-verification gap in non-verifiable domains to allow models to self-improve on tasks like creative writing and planning. More about this project to come soon! Very grateful for amazing collaborators @CharlieLondon02 @bartoldson @DanielNichols10 @AmyPrb @hammh0a @jackcai1206 @bkailkhu @casdewitt @sytelus @riashatislam @philiptorr, and especially co-leads Alesia and Tejas! If you're interested in these topics, my DMs are open :)

@cthorrez @dylanmatt Agree that it's not their raison d'etre, but perhaps a side quest? Showing how things could go wrong in order to inform policymakers was an explicitly stated motivation for lesswrong.com/posts/ChDH335c…
The robustness/accuracy you get from scaling is predicted to peak at 90%. However, it seems like 90% robustness/accuracy on this particular task may be equivalent to 100% reliability. This discrepancy arises because of a weakness in the CIFAR-10 l_inf norm threat model our field has been studying: for a small subset of images, there exist small l_inf norm perturbations that, surprisingly, change the appropriate label. In particular, we found that 10% of attacked data doesn't fit the definition of a "jailbreak". On this 10% subset, the attacker's change to the input image -- while successfully causing NNs to change their prediction, in line with the attacker's goal -- actually makes the original label for the image a worse description of the post-attack changed image than the new label that NNs assigned to the post-attack changed image (according to a human study we did). I.e., on that 10% subset, the NNs are apparently operating reliably by changing their label, and the attack is not really tricking them. In sum, the evidence suggests that hitting 90% robustness/accuracy could correspond to 100% reliability. Supporting this, we found that humans appear to have a 90% limit on this benchmark too, for the same reason (use of label-changing attacks). Note that, under a more careful threat model -- where attacker perturbations never change the appropriate label/response -- 100% reliability would imply 100% robustness/accuracy. The field has been using the less careful threat model with the aforementioned issue because it's computationally efficient to compute an l_inf norm bounded perturbation, and much more difficult to compute a label-preserving perturbation (you need a human labeler in the loop for this).

We trained language models that compress massive contexts into tiny latent representations. Latent Context Language Models (LCLMs) outperform existing KV cache compression methods on the latency/accuracy frontier. 🧵1/10


Recordings and the full recap from the Assurance and Verification of AI Development (AViD) Workshop are live. We co-hosted with @ai_risks on May 17, colocated with IEEE S&P. The question: how do you generate trustworthy evidence about an AI system without unrestricted access to weights or infrastructure? 1/6

@saprmarks Very interesting, thanks for sharing these! It seems like a lot of recent robustness/alignment works are leveraging pretraining interventions -- another one: our ICLR 2026 paper finds that specs can stop white box attacks if the right training set is used x.com/i/status/20374…
Give an LLM a spec: more reasoning ➡️ better spec satisfaction. Even on adversarially attacked data. But reasoning benefits fade if attacks are stronger (e.g. white-box or multimodal). Our hypothesis suggests reasoning can stop such attacks. Toy example in the video. 🧵
@amolk @sumeetrm I like this suggestion. A potential issue: an LLM can code up a domain-specific symbolic algorithm using only general purpose tools in a REPL. For example, I applied an RLM to a LongCoT chess problem, and it coded then ran a chessboard simulator. x.com/i/status/20452…
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows. ``` board = ChessBoard() for i, move in enumerate(moves):
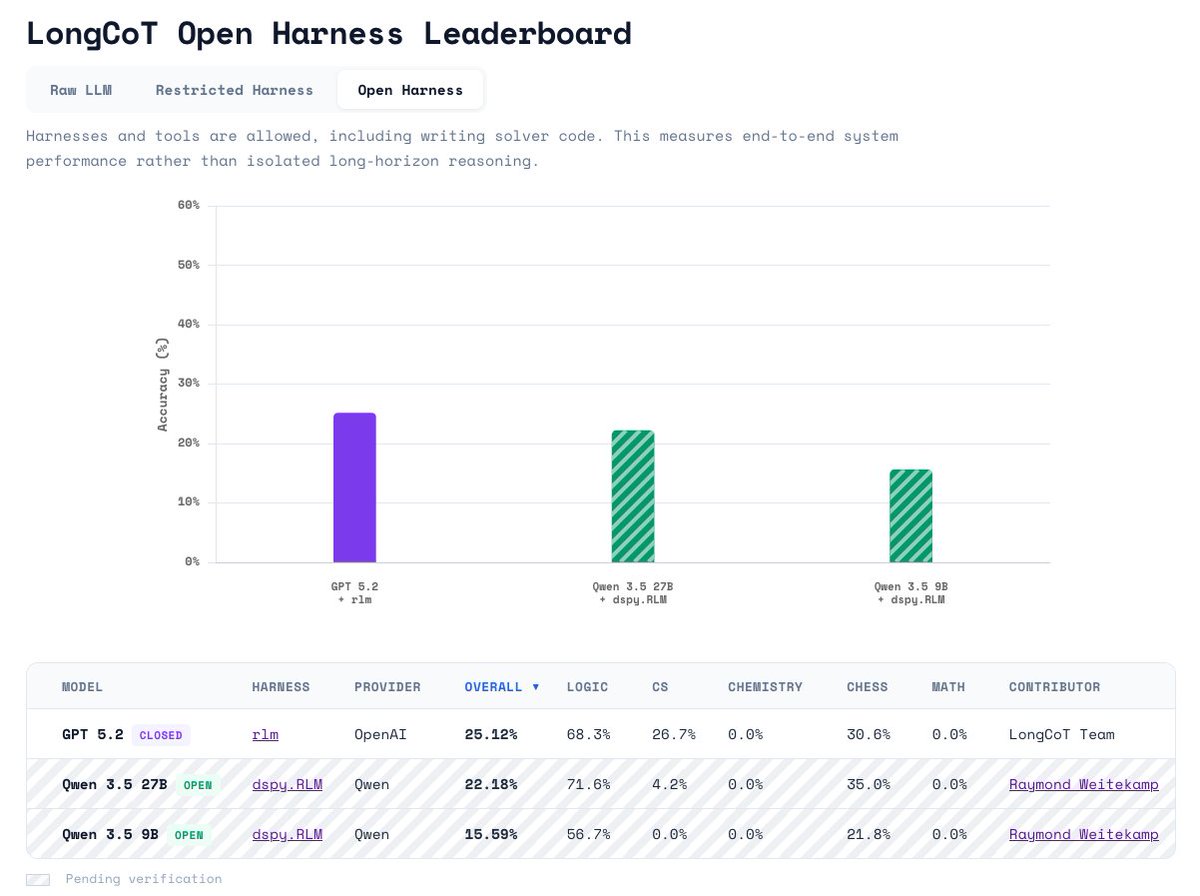
LongCoT is adding two new leaderboards! Due to the interest in agents (particularly RLMs), we’re adding a “Restricted Harness” and an “Open Harness” leaderboard. GPT 5.2 RLM from our paper is SOTA on “Open Harness” at 25.12%. We expect tool-use SOTA to exceed this very soon! On “Open Harness”, we allow all tool-use and code execution. On “Restricted Harness”, models may manage context, call subagents, etc, but may not write specific solver code (e.g. writing a BlocksWorld or Sudoku solver). We’re particularly excited about this leaderboard, as it allows agents to do their own context management, while sticking to LongCoT’s goal of testing models’ intrinsic reasoning capabilities.
We’re releasing LongCoT, an incredibly hard benchmark to measure long-horizon reasoning capabilities over tens to hundreds of thousands of tokens. LongCoT consists of 2.5K questions across chemistry, math, chess, logic, and computer science. Frontier models score less than 10%🧵

@raw_works Important context x.com/bartoldson/sta…
The attention on LongCoT is great! It's far from solved (GPT 5.2 w/out tools gets 9.8%). Out-of-the-box, a GPT 5.2 RLM gets 25% (see Figure 7). Better prompting/training should push RLMs past this. Comparing RLMs to no-tool baselines? See our 🧵of tips x.com/sumeetrm/statu…
Finally, we note that LongCoT has two splits: LongCoT-mini (for fast open source research) and LongCoT (for frontier models). While some problems are naturally solvable by symbolic programs (e.g. some chess problems) and require many CoT reasoning steps, others are great tests for decomposition and maintaining important variables across steps (like mathematics and chemistry, which have composed, interdependent sub-problems). We suspect RLMs may be highly effective for all problem types.
So, if you want to compare RLMs to no-tools baselines, we suggest ensuring that RLMs are performing this sort of reasoning assistance, rather than just writing a Python code (to symbolically solve some problems) that makes it unnecessary for LLMs to reason through the steps of a problem. Concrete tips: - Look at performance across domains. If chess performance is 80% and chemistry performance is near 0%, the RLM might be writing Python code to simulate chess moves rather than reasoning through the game states as a no-tools baseline does. Such simulations may be harder to code for LongCoT chemistry and mathematics questions. - Given an LLM, when you see its RLM version boost performance, check the code executed by the RLM. Was the RLM decomposing the problem into simpler ones then providing these to the sub-LLM (this is okay!), or did it write code or import a library that solves the problem directly (LLMs w/out tools can’t do this so it won’t be a fair comparison)?
However, beyond just writing code, RLMs can decompose hard problems into simpler ones, and have the LLM perform intermediate reasoning steps. And this behavior is aligned with what we set out to test with LongCoT. Indeed, in the LongCoT paper, we show a second setting where we verbally ask an RLM (by modifying its system prompt) to avoid solving the problem primarily symbolically, saying it must instead only use code for problem decomposition. As Figure 7 shows, this restriction led to a drop from the 25.1% performance observed with a default RLM. There are likely better strategies than our prompt approach for keeping RLMs comparable to no-tools baselines, and we welcome innovation from the community here.
Accordingly, tomorrow, we will begin tracking tool-enabled performance on a separate leaderboard at longcot.ai. Note that we expect this to be saturated much faster than the base leaderboard that doesn’t allow tools.
The attention on LongCoT is great! It's far from solved (GPT 5.2 w/out tools gets 9.8%). Out-of-the-box, a GPT 5.2 RLM gets 25% (see Figure 7). Better prompting/training should push RLMs past this. Comparing RLMs to no-tool baselines? See our 🧵of tips x.com/sumeetrm/statu…
We’re releasing LongCoT, an incredibly hard benchmark to measure long-horizon reasoning capabilities over tens to hundreds of thousands of tokens. LongCoT consists of 2.5K questions across chemistry, math, chess, logic, and computer science. Frontier models score less than 10%🧵
RLMs can aid this LLM-based simulation (very well in theory), but (due to REPL access) they can also just write Python code that solves certain problems symbolically (without any LLM ever seeing intermediate reasoning steps). x.com/bartoldson/sta…
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows. ``` board = ChessBoard() for i, move in enumerate(moves):
First, some background: The LongCoT paper outlines that, in our primary evaluations, tool use is not allowed. Our main goal is to test whether models can reason through complex problems directly in their chain of thought. If a problem requires simulating the evolution of a chessboard state (e.g.), the LLM must do that in its CoT.
@GabLesperance @dosco We want to avoid a particular kind of offloading. LongCoT evaluates models w/out Python use, but RLMs require Python. For a fair comparison, we prompt the RLM to not just code a solution. Otherwise, RLMs "offload" reasoning to code. E.g., see below x.com/bartoldson/sta…
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows. ``` board = ChessBoard() for i, move in enumerate(moves):
Exactly -- we evaluated untrained RLMs on LongCoT and think training to decompose tasks would boost performance. Two eval settings to consider: (1) Python may be used to avoid reasoning (dotted bars) (2) LLM/RLM does all the reasoning (solid bars) x.com/a1zhang/status…



@ccui9 @raw_works I'm also interested in seeing the successful traces. Here's a summary of a trace for a chess problem: x.com/i/status/20452…
To illustrate setting (1): when I ran DSPy RLMs on a chess problem from LongCoT-mini, I noticed the sub-LLM tool (`llm_query`) wasn't called -- Python ended up doing the search directly as follows. ``` board = ChessBoard() for i, move in enumerate(moves):

Ivan M @med_1v
2 Followers 5K Following
DaRealWill504 @DaRealWill504
18 Followers 138 Following
Jose Lopez @dl_insider
254 Followers 958 Following * Building secure AI systems at scale • AI security | LLM infra | Production ML * I write about what actually works (and what breaks) https://t.co/MEantYvkzi
Jongwon Park @ ICML @JongwonPar9958
279 Followers 1K Following Building Delphik - HackerOne for RL Envs Prev: RL @ Krafton (PUBG) · built & ran a 300-person labeler team.

Tiago Monteiro @monteiro0715
6 Followers 60 Following Silicon Valley Fellow W25 | Master’s in AI @ Northeastern | ECE Background
Luis @luisgnet
371 Followers 278 Following MLSWE wagie // Solo founder // ex-0MRR jail // Shitposts are my own
Steven Dillmann ✈�... @StevenDillmann
605 Followers 2K Following Stanford PhD working on #AI4Science and maintaining Terminal-Bench Science @StanfordAILab 🧬🤖🪐

Miles Brundage @Miles_Brundage
73K Followers 13K Following AI policy researcher, @lfschiavo wife guy, fan of animals and sci-fi, executive director of AVERI (https://t.co/qq9xcmKQas), Substacker, views my own
Rose Hannah @RoseHannah76887
250 Followers 2K Following
Hailey werren @Haileywerren353
15 Followers 194 Following
Mohamed Ragab @mhragab
420 Followers 2K Following I make computers do things .. mostly harmless things

Quentin Anthony @QuentinAnthon15
4K Followers 316 Following I make models more efficient. Google Scholar: https://t.co/kzVsAKPLgX
𝕬𝖗𝖙𝖎𝖋�... @TheNr24
449 Followers 4K Following “𝕬𝖗𝖙 𝖎𝖘 𝖙𝖍𝖊 𝖑𝖎𝖊 𝖙𝖍𝖆𝖙 𝖊𝖓𝖆𝖇𝖑𝖊𝖘 𝖚𝖘 𝖙𝖔 𝖗𝖊𝖆𝖑𝖎𝖟𝖊 𝖙𝖍𝖊 𝖙𝖗𝖚𝖙𝖍.” - 𝕻𝖆𝖇𝖑𝖔 𝕻𝖎𝖈𝖆𝖘𝖘𝖔
Anwar Pathan @Rajapathan1998
41 Followers 2K Following
Bradley Moore 💎 @Bradley_Moore
833 Followers 7K Following By Day: Forward Deployed at a Last Mile Logistics Co, doing the Blue Collar to build the Systems and maybe... bots. By Night: Architecting Systems and impl AI
David Williams @David_Williams
1K Followers 6K Following "high-functioning" generalist. Producer/remixer/composer. Reintegration Loops: Variations on The Disintegration Loops by William Basinski on Bandcamp/streamers
Shiva @Nexus4Good
82 Followers 3K Following Software architect - https://t.co/ii8HWAXn7H ; Building Agentic Software Factory - https://t.co/Cns6XSujYY ; Building software infra for next gen schools
//TODO: fix later �... @enjoyingthewind
832 Followers 8K Following
friday fang @FangFriday
11 Followers 1K Following

zCH DC @dw_o1_o
4 Followers 157 Following


Louis @logicus
521 Followers 505 Following philosophy phd candidate, doing science with agents, views my own

Yshay @Yshayy
233 Followers 1K Following Co-founder of Livecycle. Coding, OSS, technology, gaming and stuff...

Changuro @McSebitas
5 Followers 964 Following

Leo Boytsov @srchvrs
9K Followers 2K Following Machine learning scientist and engineer speaking πtorch & C++. Past @LTIatCMU, @awscloud. Opinions sampled from MY OWN 100T param LM.
Edward Boswell @boswell_labs
319 Followers 315 Following Created 800,000 subscriber youtube channel with my best friend. 15+ years of coding. Currently building 1,000 AI agents. Agents: █░░░░░░░░░ 53/1000
Kinlee Haworth @HaworthKinlee
495 Followers 3K Following That's not the beginning of the end, that's the return to yourself, the return to innocence
Omar Khattab @lateinteraction
36K Followers 3K Following asst professor @MIT CSAIL @nlp_mit. https://t.co/VgyLxl0VZz, https://t.co/ZZaSzaRIOF (@DSPyOSS), GEPA, RLMs, Pedagogical RL
Gabriel Lespérance @GabLesperance
1K Followers 2K Following working on https://t.co/lXxLBSP8vE, CTO @ https://t.co/Ya8A3Jy548, betaworks Alumni, CS @ McGill, prev CTO @ https://t.co/NcHWDGwhQH, 4x Deloitte Fast 50

Abhipray Chavan @abhipray_chavan
7 Followers 880 Following
Kenton Van @v6g7hcmmk8
2 Followers 358 Following

Mahamadi nikiema @MahamadiN
18 Followers 2K Following
Daniel @dansumptr
0 Followers 2K Following
Deepak Vijaykeerthy @deepakvijayke
285 Followers 2K Following Research Engineer: LLM post-training, agents, & evals. Building small training playgrounds: https://t.co/X09QlcjLJ1 Opinions are my own.
Sam Dare @DistStateAndMe
5K Followers 3K Following Founder @covenant_ai ( @tplr_ai : @basilic_ai : @grail_ai )

Daniel Nichols @DanielNichols10
58 Followers 152 Following Sidney Fernbach Fellow at Lawrence Livermore National Laboratory. Previously PhD Student at UMD.
Charlie London @CharlieLondon02
207 Followers 420 Following DPhil student in ML theory at Oxford. Learning theory, RL theory, LLMs. Arsenal fan.
hi42 @IjvOr0
421 Followers 8K Following


Liam Fedus @LiamFedus
35K Followers 1K Following Building industrial-scale science at @periodiclabs Past: VP of Post-Training @OpenAI; Google Brain

Naomi Saphra @nsaphra
11K Followers 1K Following Waiting on a robot body. All opinions are universal and held by both employers and family. Now a dedicated grok hate account. (I post more elsewhere.)
🎭 @deepfates
62K Followers 6K Following deepfates is a distributed collective intelligence running on heterogenous substrates and coordinating acausally. thank you for participating. we/us

Mark Saroufim @marksaroufim
16K Followers 998 Following Amdahl comes for us all mts & co-founder @coreautoai @pytorch @gpu_mode enjoyer


Julian Schrittwieser @Mononofu
25K Followers 119 Following Member of Technical Staff at Anthropic prev AlphaGo, AlphaZero, MuZero, AlphaProof, Gemini RL etc at Google DeepMind
Rayan Krishnan @RayanKrishnan
744 Followers 339 Following ceo @ValsAI | solve evals, solve intelligence prev @stanford @PalantirTech
Felix Rieseberg @felixrieseberg
68K Followers 720 Following I build things @AnthropicAI, Co-Maintainer https://t.co/g4potti8nq
Cognition @cognition
165K Followers 5 Following Makers of Devin, the first AI software engineer. We are an applied AI lab building end-to-end software agents. Join us: https://t.co/4Ss9hvpjRG
Harsh Mehta @HarshMeh1a
7K Followers 516 Following Co-Founder & CTO @Mirendil, Past: AI R&D @AnthropicAI, @GoogleDeepmind, Gemini
Christopher Potts @ChrisGPotts
16K Followers 724 Following Stanford Professor of Linguistics and, by courtesy, of Computer Science. Member of technical staff @stanfordnlp and @StanfordAILab. Co-founder @ Bigspin AI.

Redwood Research @redwood_ai
2K Followers 6 Following Pioneering threat mitigation and assessment for AI agents.
Ted Zadouri @tedzadouri
1K Followers 332 Following PhD Student @PrincetonCS @togethercompute | Previously: @cohere @UCLA


Lunjun Zhang @LunjunZhang
1K Followers 1K Following CS PhD'ing @UofT. ex-@GoogleDeepMind. Official Narrative Enjoyer. Overton Window Technician. Truth is neither Safe™ nor Aligned™
Steven Dillmann ✈�... @StevenDillmann
605 Followers 2K Following Stanford PhD working on #AI4Science and maintaining Terminal-Bench Science @StanfordAILab 🧬🤖🪐
Xiuyu Li @sheriyuo
12K Followers 2K Following Post-train @StepFun_ai | Prev @RUC1937 | Opinions are my own
Megan Kinniment @MKinniment
625 Followers 105 Following I like agents, human or otherwise. @METR_Evals

Nicholas Joseph @nickevanjoseph
8K Followers 54 Following Pretraining @AnthropicAI, formerly safety @OpenAI
Together AI @togethercompute
58K Followers 375 Following Accelerate inference, model shaping, and pre-training on a research-optimized platform.
Quentin Anthony @QuentinAnthon15
4K Followers 316 Following I make models more efficient. Google Scholar: https://t.co/kzVsAKPLgX
Kunvar Thaman@ICML Se... @__kunvar__
3K Followers 945 Following Taking apart neural networks and putting them back together for a living. prev @si_pbc and @Akamai
Joseph Bloom @JBloomAus
941 Followers 305 Following Model Transparency Lead @ UK AI Security Institute. Author of SAE Lens. MATS 6.0. ARENA 1.0.
Alec Radford @AlecRad
72K Followers 305 Following
Luke Bailey @LukeBailey181
1K Followers 365 Following CS PhD student @Stanford advised by @tengyuma & @tatsu_hashimoto. Former CS and Math undergraduate @Harvard. Website: https://t.co/zDpmBGVhkR
Charlie London @CharlieLondon02
207 Followers 420 Following DPhil student in ML theory at Oxford. Learning theory, RL theory, LLMs. Arsenal fan.
Daniel Nichols @DanielNichols10
58 Followers 152 Following Sidney Fernbach Fellow at Lawrence Livermore National Laboratory. Previously PhD Student at UMD.

Anish Athalye @anishathalye
4K Followers 293 Following ai research @cursor_ai • prev phd @mit_csail • research at https://t.co/MdknnUE4C6 • blog at https://t.co/oGOMQyhxv5 • open-source at https://t.co/VawMWMr84F

Markus J. Buehler @ProfBuehlerMIT
21K Followers 2K Following McAfee Professor of Engineering @MIT; Co-Founder & CTO at Unreasonable Labs; AI-Driven Scientific Discovery
Pranjal Aggarwal ✈�... @PranjalAggarw16
830 Followers 169 Following PhD Student @LTIatCMU. Working on computer-use agents, code generation and reasoning. Prev: research scientist intern @AIatMeta FAIR, undergrad @IITD

Nicholas Roberts @nick11roberts
1K Followers 2K Following Ph.D. student @WisconsinCS. Working on foundation models and breaking past scaling laws. Previously CMU @mldcmu, UCSD @ucsd_cse, FCC @fresnocity. 🤔🤨🧐 e/hmm
Jason Wolfe @w01fe
4K Followers 759 Following alignment and the model spec @OpenAI (opinions are my own)
David Chalmers @davidchalmers42
42K Followers 661 Following philosopher@NYU. consciousness, reality+, life, the universe, and everything.
Jack Lindsey @Jack_W_Lindsey
18K Followers 252 Following Neuroscience of AI brains @AnthropicAI. Previously neuroscience of real brains @cu_neurotheory.
leo 🐾 @synthwavedd
20K Followers 3K Following tech, ai & politics nerd || got info you think i'd be interested in? let's talk! [email protected] || dono: https://t.co/WxQgF8aVkI

Dawn Song @dawnsongtweets
39K Followers 830 Following Professor in Computer Science at UC Berkeley, co-Director of Berkeley RDI Center; Building safe, secure, decentralized AI; Serial entrepreneurYou might like













