

terminalbench @terminalbench
https://t.co/3jNN3bYpO5 Joined May 2025-
Tweets15
-
Followers340
-
Following4
-
Likes8

GPT‑5.6 Sol sets a new state of the art on Terminal‑Bench 2.1, which tests complex command-line workflows requiring planning, iteration, and tool coordination.


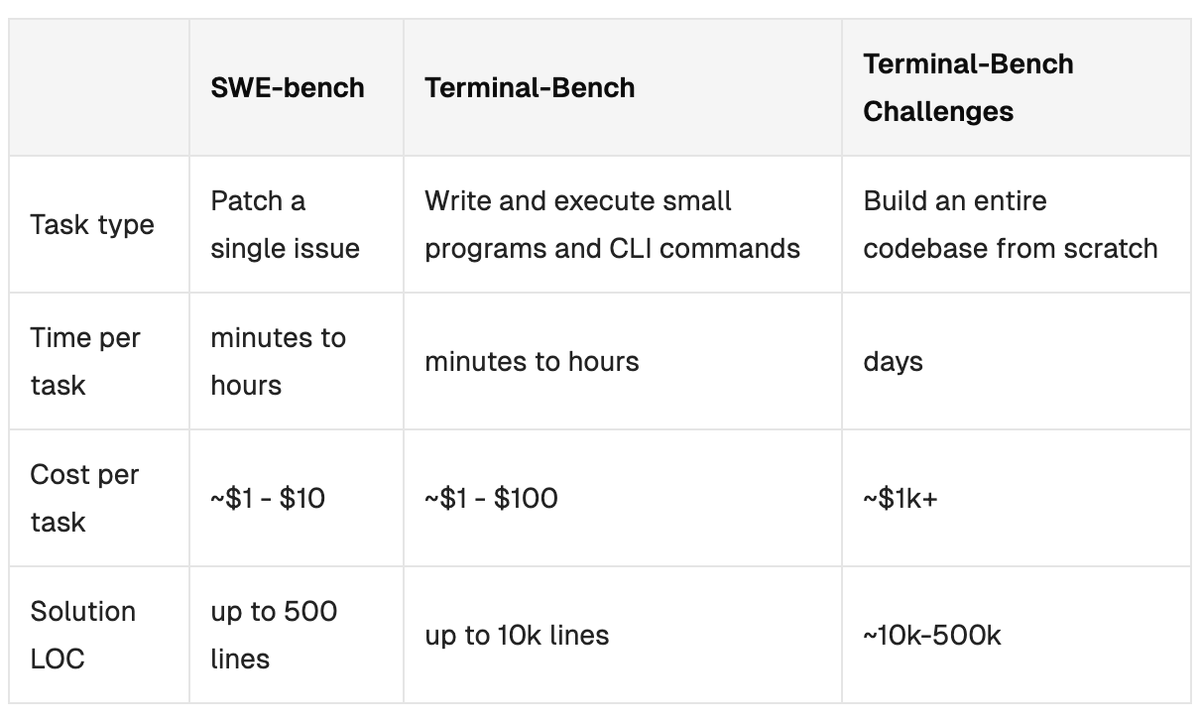
Can agents build complete projects that deliver real value? We’re launching Terminal Bench Challenges: 3 unsolved tasks which could make a real impact on the open source community if solved. These tasks provide a testing ground for optimizations both on the model and harness level on our continuous leaderboard for each task.

Terminal-Bench Challenges is inspired by previous projects exploring long-running agents including Carlini's C compiler and Cursor's browser. Join the effort! If you have ideas for further challenges, come hang out in the tb-challenges discord channel discord.com/invite/2Pe5uWG…
Check out the full release blog for more details! tbench.ai/news/terminal-…
Introducing Terminal-Bench Challenges! A new capability has emerged at the frontier: agents completing large-scale projects autonomously. To test this capability, we felt another flavor of benchmark was needed. Terminal-Bench Challenges are long-horizon, token-intensive, single-task benchmarks. Today we are releasing our first 3 challenges.
Contribute to Terminal-Bench Science!

📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇 tbench.ai/news/tb-scienc… @AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to

Thank you to @ekellbuch for leading TB2.1, @Zai_org for Terminal-Bench 2.0 Verified, which informed 11 of the 28 tasks we patched, and @SnorkelAI and @togethercompute for support

We're releasing Terminal-Bench 2.1 to patch 28 of the 89 tasks in Terminal-Bench 2.0 TB2.1 includes • recalibrated limits • fixed solutions • realigned verifiers Per-task breakdowns in 🧵 We'll continue to support TB2 and TB2.1 leaderboards (new submission process 🔜)

The Terminal-Bench community discovered multiple instances of cheating and reward hacking on the Terminal-Bench 2.0 leaderboard. We're adding some new policies to keep it reliable: • ATIF trajectories required for all passing trials • Reward hacking results in reward 0 for the trial • Cheating results in immediate leaderboard removal Thanks to @davisbrownr, @adamlsteinl, and @NoCommas for flagging the recent occurrences! Detailed blog post in comments ⬇️
We independently verified these claims and removed OpenBlocks from the Terminal-Bench 2.0 leaderboard. Thank you @NoCommas for helping us keep leaderboard entries honest! Recent leaderboard submissions are in huggingface.co/datasets/harbo… which makes it easy for the community to work together to detect cheating.

Shlok Natarajan @Shlok_Natarajan
128 Followers 348 Following Research @StanfordDBDS @StanfordAILab Prev @Salesforce @Amazon @GeorgiaTech
🦄 kai chen @kaichensf
103 Followers 323 Following swe @cortexairobot, prev @manusai & @tiktok_us ambassador @lovable @notionhq
Adam Falls @AdamFalls172137
52 Followers 5K Following


NOW B @NOAHB971
67 Followers 653 Following Je investisseure au long terme. DeFi Research & Analysis | Lending · Yield · On-chain Data | AI-powered tools builder
Jeremy Eder 🤘 @jeremyeder
2K Followers 215 Following Distinguished Engineer at Red Hat. Past: SaaS/SRE, Performance/Scale, Hardware Accelerators, R&D.
Андрей @Andrej530215
2 Followers 45 Following
livem @livem19
14 Followers 881 Following
nelo @sahaubah
367 Followers 6K Following
Frank @frank_
3K Followers 867 Following design, invention, and imagination — now @thinkymachines, previously @NotionHQ.
GoodyTech (❤️�... @GoodyTech_
1K Followers 2K Following Problem solving in crypto- Moderator - Community strategist - CF @groundzero_io
Louisa.g @PikakeWin
372 Followers 1K Following VP at @gmi_cloud Ex-founder. Built Agents to 10M+ MAU. Now building the AI-native compute layer for the next big thing. 💜
qing wen @wenqing_9527
20 Followers 352 Following

Jaya Gupta @JayaGup10
34K Followers 4K Following tweets about AI and other fun stuff. currently @foundationcap; wrote the context graph paper. previously McKinsey, @georgiatech, @stackfolio (acquired),
JG @jongall45
3K Followers 7K Following frontrunning @frontrunvc | partner @PalmTreeCrypto | vibing @ostiatrade
ARΞS @Afrectz
3K Followers 7K Following Trends before they go mainstream Crypto & Web3 - @AresLabs_xyz, AI & Robotics - @AreslabsAI , ex.Researcher - @ABCDELabs.
Mahmoud Shabana @shabanah_2
8 Followers 37 Following
Elliot Jerng @ElliotJerng
0 Followers 21 Following


Kirk Marple @KirkMarple
4K Followers 4K Following Founder/CEO of Graphlit (@graphlit): Operational Context Layer for AI Agents 🚀 @zine_ai @dossium 👋 ex-MSFT, PA born, Seattle bred. Dad to dogs/humans
ML ENERGY @ml_energy
22 Followers 57 Following https://t.co/BurgSsEx00 | We build machine learning systems that treat energy as a first-class computing resource.
RISHAV Kumar @RISHAVKuma27369
1 Followers 41 Following I am a Final year https://t.co/OREhaSMds8 student at IIIT Bhagalpur.

Michael Yu @nicetomeetyu2
161 Followers 631 Following
Davide @davidesala23
60 Followers 918 Following Founding Product Manager at @datapizza_ai | previously Data at @precis_digital
luka @bestluka0101
10 Followers 344 Following
Subin An @subinium
26K Followers 4K Following 🇰🇷 Engineer at Asteromorph | Prev. Tech Lead @hashed_official | @kaggle Notebook Grandmaster | Prev. @dune Team #1 | MS in SNU CS (HCI)
darkstar @darkstar_AU
24 Followers 3K Following
shwetu (luca) @_shwetu
325 Followers 5K Following organic general intelligence | jack of all trades, master's from @NYUDataScience prev: Research @NYTimesRD @precog_iiitd; Manipal grad | he/him
Srikanth Tanniru @tannirusrikanth
26 Followers 546 Following DevOps Enabler | Cloud-Native Enthusiast | FinTech Learner
Jofre Espigule Pons @jofre_ep
189 Followers 2K Following Working with LLMs and Generative AI. 🤖 Machine Learning Team, Wolfram Research. 🐺 Nature enthusiast and iNaturalist user. Expertise in Spiders. 🕷️🕸️

jasper mebane @jasper_mebane
15 Followers 127 Following
목화 @mochafreddo
601 Followers 2K Following software engineer do no harm. reject prejudice 무해를 지향합니다 편견을 지양합니다
mehdi cherti @mehdidc
340 Followers 924 Following PostDoc at Jülich Supercomputing Center (JSC), Germany / LAION.
Jongwon Park @ ICML @JongwonPar9958
271 Followers 1K Following Building Delphik - HackerOne for RL Envs Prev: RL @ Krafton (PUBG) · built & ran a 300-person labeler team.

Sanyam Satia @sanyamsatia
88 Followers 182 Following breaking things apart and putting them back together (sometimes)
Monk Zero @NoCommas
1K Followers 1K Following @antigma_labs, prev: @awsCloud, @Meta, @Mysten_Labs. A Turing Complete mind, wandering the world of Gödel Incompleteness.
Guilherme @gpmarques1993
37 Followers 2K Following
Gonzalo Rafuls @grafuls08
225 Followers 2K Following Part-time thinker, Principal Software Engineer @RedHat

Enigma @bala529
140 Followers 1K Following
Zhiwei Xu @zhiweixux
171 Followers 973 Following PhD Student @ UMich | prev. USTC Diff between reasoning & pattern matching?
Sam @Torries_ICML
0 Followers 8K Following

Per0x1d3 @0x1_0xyd3
42 Followers 276 Following prev engineering @HacktronAI | Undergrad of IIT Roorkee| CTF player at @InfosecIITR
Ludwig Schmidt @lschmidt3
6K Followers 426 Following Assistant professor at @Stanford and member of the technical staff at @AnthropicAI.
Ryan Marten @ryanmart3n
2K Followers 2K Following Building @harborframework and @terminalbench with @alexgshaw
Mike A. Merrill @Mike_A_Merrill
3K Followers 399 Following Evals at Anthropic, Co-Creator of Terminal Bench, Go Bills
Alex Shaw @alexgshaw
2K Followers 667 Following Hacking on @terminalbench and @harborframework. Founding MTS @LaudeInstitute. Formerly Google. BYU alum.Trends for United States
You might like



















