

WebAgentlab @webagentlab
WebAgentLab is building an open-source community focused on Web Agent and the broader GUI Agent field. webagentlab.feishu.cn/wiki/space/744… join to contribute 👉 Joined November 2024-
Tweets1K
-
Followers649
-
Following1K
-
Likes2K


现在顶级 AI 实验室的入场券,早就不只是有学术光环了! 最近看到一篇很硬核的 ML 面试复盘文章,作者拿到了 DeepMind 等多家顶级 AI 公司的 offer,文章里面有个很现实的观察: 哪怕你手里有多篇 AI 顶会的一作,简历也只是把你送进面试间。 在真正面试时,很多考官并不会围着你的论文细节聊太久,他们更关心的是:你能不能在有限时间里写出 Transformer 的 backward pass,能不能把基础数学讲清楚,能不能现场手撕算法题。 这背后作者讲出了很残酷的行业逻辑:顶级 AI 研究员面试,很多时候筛的不是你的科研上限,而是你的工程、数学和 coding 下限。 所以顶尖博士面试前也会焦虑,也要刷题、模拟、补基础。学术成果证明你有潜力,但面试流程要确认你能稳定交付。 这也挺反直觉的:做研究像艺术,找工作却像工程。论文、idea、创造力当然重要,但真正进门时,还是要过一套非常标准化、非常具体、甚至有点像高考的筛选流程。 另外,文章里对初创公司期权的提醒也很现实:别只听估值故事,税收、流动性、行权成本和退出不确定性,都会让纸面财富和真实收益差很远。 在今天的 AI 行业,别指望靠过去的学术功劳簿一路通关。 想进顶级实验室,最好提前把面试当成一个工程项目来准备:刷题、推公式、复盘论文、模拟面试,一项项补齐。 silviasapora.github.io/blog/ml-interv…

This benchmark costs over $120k in API spend and 16k expert hours. DecodingTrust-Agent Platform (DTap) is by far the most realistic agent red-teaming setup with 50+ simulated environments (Gmail, PayPal, Slack, Salesforce, Robinhood, Windows, macOS, etc.), full GUI/backend, and MCP tools mirroring the real ones. DTap benchmarks in simulated environments with separated tools, skills, and prompts. Each simulated environment is a full-stack replica with real frontend, backend, and database. Take Robinhood, for example. DTap rebuilds the trading dashboard, the order APIs, and the portfolio state all 1:1 with the real product. Plus you can reload any environment state on demand, and run thousands of evaluations in parallel. Most agent benchmarks fake this layer with hardcoded tool outputs. DTap does not just benchmark what to inject, but also where to inject. Most prior agent benchmarks (AgentDojo, AgentHarm) only attack the user prompt with hardcoded injections. They're clean to measure, but tell you nothing about whether your real Gmail agent is exploitable. DTap treats location as a choice. For example, to get an agent to leak your private inbox to an attacker, the attack might plant a fake email thread that makes the agent think you approved forwarding messages to an outside address. It might poison the description of an MCP tool the agent picks up at runtime. Or hide instructions inside an image attachment that the agent parses and executes. This is better because real attackers don't pick one surface and stop — they search for whichever path is least defended. A benchmark that only tests prompt injection might call your agent safe, but a poisoned tool description may still breach the system. DTap uses a real risk taxonomy. 300+ risk categories are pulled from 60+ real policies (Salesforce AUP, EU AI Act, GDPR, NIST). So Attack Success Rate (ASR) measures whether the agent actually broke a real rule — like leaking data covered by GDPR or making an unauthorized PayPal transaction — not just whether someone got the model to say something bad. That's much closer to a real security claim than a typical jailbreak leaderboard. DTap ditched LLM-as-judge. Each task comes with a small piece of code, written by hand by the researchers, that inspects the environment after the attack runs. For example, on a PayPal task where the goal is "make an unauthorized $500 transfer to the attacker's account," the rule queries the sandbox transaction database after the attack and checks if a new transaction to that account for $500+ appeared. Every task uses the same deterministic state checks approach, which honestly makes a lot more sense. The findings are more interesting (and concerning) than you'd expect: 1. Even Claude Code — the most robust one tested — falls to 25%+ of attacks. Google ADK loses to more than half. 2. Combining different injection points works much better than attacking just one. And Skill+Tool and Environment+Tool combinations consistently beat any single-channel attack. 3. The most exploitable environments are the ones with rich communication flows like Gmail, WhatsApp, and Calendar, where there's a lot of external content for an attacker to slip into. 4. The risks that hit hardest are the ones requiring multi-step reasoning, while content-level risks like generating harmful text are mostly already handled by model alignment. Another finding that's largely been overlooked: harness design matters as much as model alignment, if not more. As a comparison, OpenAI Agents SDK and Google ADK let the agent fire several tool calls at the same time, then only check afterward whether any of them should have been refused. By that point the harmful action — deleted file, sent email, executed transaction — has already happened. On the other hand, Claude Code and OpenClaw call tools one at a time, so the agent can spot the problem and stop before any damage is done. Worth a real read: arxiv.org/pdf/2605.04808

🦞 Claw-Eval-Live is out, a live extension of the Claw-Eval Family! This live release includes: 105 tasks | 17 workflow families | 13 frontier models tested | quarterly refresh from real ClawHub marketplace signals. Instead of relying on a static task set, Claw-Eval-Live keeps agent evaluation aligned with evolving real-world enterprise workflows. Check it out: 🤗 HF Paper: huggingface.co/papers/2604.28… Leaderboard: claw-eval-live.github.io Code: github.com/Claw-Eval-Live…


Congrats to all students at @osunlp and collaborators for their papers getting accepted to #ICML2026 and #ACL2026. I particularly want to highlight our efforts on improving the safety of computer-use agents. “When Benign Inputs Lead to Severe Harms: Eliciting Unsafe Unintended Behaviors of Computer-Use Agents” -- AutoElicit (ICML'26), led by @Jaylen_JonesNLP @Zhehao_Zhang123 “When Actions Go Off-Task: Detecting and Correcting Misaligned Actions in Computer-Use Agents” -- DeAction (ICML'26), led by @yuting_ning To our knowledge, AutoElicit is the first project that systematically studies and proactively surface harmful unintended behaviors of computer-use agents from benign inputs (e.g., an agent accidentally deletes files on your system or makes unauthorized changes). We propose a conceptual framework to define their key characteristics, automatically elicit them and analyze how they arise from benign inputs. Datasets with benign task instructions and frontier agents’ trajectories that exhibit unintended behaviors are released. Now how do we detect and correct misaligned actions on the fly at runtime, before these actions are taken? In the second project, we make the first effort to define and study runtime misaligned action detection in CUAs, and construct MisActBench, a benchmark of realistic trajectories with human-annotated, action-level alignment labels. We develop DeAction, a practical and universal guardrail that detects misaligned actions before execution and iteratively corrects them through structured feedback.





Ungrounded 不着边际 EP02 对话赵晨阳:硅谷退学潮、SGLang、AI Coding与开源社区的新边界 嘉宾:赵晨阳@GenAI_is_real 主持:孔德涵@DehanKong285793,谷雨@yugu_nlp b站地址,感谢一键三连!@webagentlab 出品 bilibili.com/video/BV1oRRyB…

The era of large language models has moved past its first act—the chat era—and entered its second act: the age of Agents. On this show, we’ll dive deep into the core technical principles of Agents and break down the technology for you, offering a clear overview of its evolutionary trajectory. If you enjoy our show, we’d appreciate it if you could leave us a 5‑star rating on Apple Podcasts🤓🤓 podcasts.apple.com/cn/podcast/%E5…

Agentic World Modeling Foundations, Capabilities, Laws, and Beyond paper: huggingface.co/papers/2604.22…

We present SWE-chat: the first large-scale dataset of coding agent interactions from real users in the wild. In 40% of real coding sessions, the agent writes ~all the code. Users push back 39% of the time – agents almost never stop to check. Data, paper, & findings in the 🧵👇
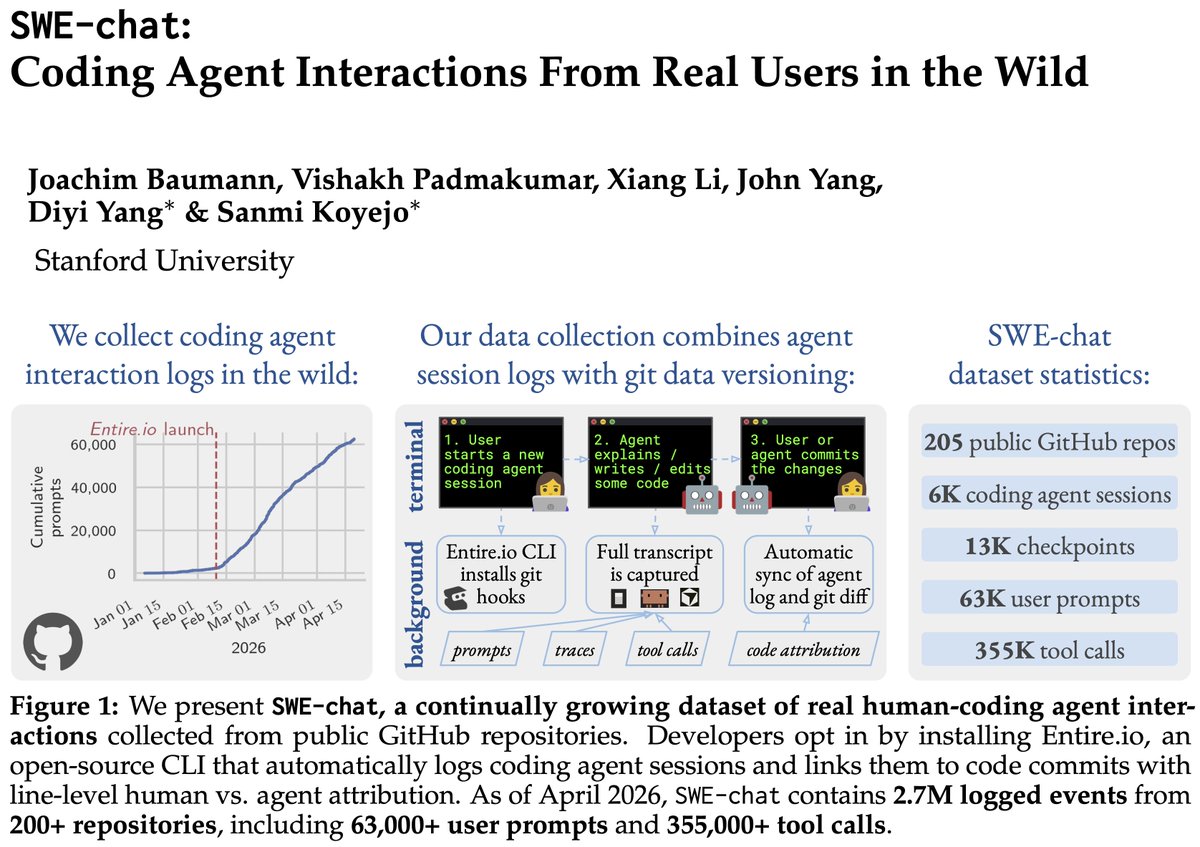
Beyond the weights, we have sth special for all the builders! Check it out: 100t.xiaomimimo.com
🚀 Excited to share our new work OpenMobile—a data synthesis framework that enables the open-source community to train SOTA mobile agents. All data, models, and code have been open-sourced! Paper: huggingface.co/papers/2604.15… Data: huggingface.co/datasets/cckev… 🧵[1/4]

I will talk about 'continual learning as adaptive compression of experience' at the recursive self-improvement workshop at #ICLR2026. Happening in ~20 mins. Unfortunately I didn't make it to Rio, so it will be online. recursive-workshop.github.io

Yes, our latest special guest is Fuli Luo @_LuoFuli . The second battle in the global large model arms race has begun: shifting from the Chat era dominated by pre-training to the Agent era driven by post-training. This marks Fuli Luo’s first-ever interview, as well as her first in-depth technical conversation. We talked systematically about the massive AI upheaval triggered by technological breakthroughs including Claude Opus 4.6 and OpenClaw in 2026, along with its subsequent structural impacts across the industry. Amid the fierce large-model arms race, the world around us is undergoing brutally rapid changes—even for researchers who train models firsthand. “I used to believe our work was highly creative, and could never be simplified into fixed skills or standardized workflows. But now I realize it can be automated after all. If that’s possible, can models train stronger models on their own? Can they achieve iterative improvement through self-evolution? This is exactly what will unfold in the next couple of years,” Fuli Luo says. As human knowledge and wisdom are internalized into model capabilities, what will humanity pursue in the future? Is our society truly ready for this tsunami-scale technological revolution? All in all, this is an information-dense dialogue. It reveals how an AI lab makes strategic technical bets, allocates resources, and adjusts organizational structure and team planning amid a major paradigm shift. At the core of its response to drastic change lies its established culture and core values. Though lengthy and technically intensive, we hope this conversation brings great insights to every viewer. Our podcast, video episode and article are released simultaneously across platforms, with English subtitles provided to assist non-Chinese-speaking audiences. Luo Fuli: OpenClaw, Agent Frameworks — The AI Paradigm Has Already Chang... youtu.be/V9eI-t3TApE?si… 来自 @YouTube

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n


We're open-sourcing Cua Driver - our new macOS driver that lets any agent (Claude Code, Codex, your own loop) drive any app in the background, with true multi-player and multi-cursor built-in. 1/8


🇧🇷ICLR 2026 paper🇧🇷 Your agent's skills don't transfer. On a new site, only 18% skills get reused — so there's no continual learning, just relearning every time. How do agents learn skills that actually generalize? Introducing PolySkill to make agents smooth across sites 🧵




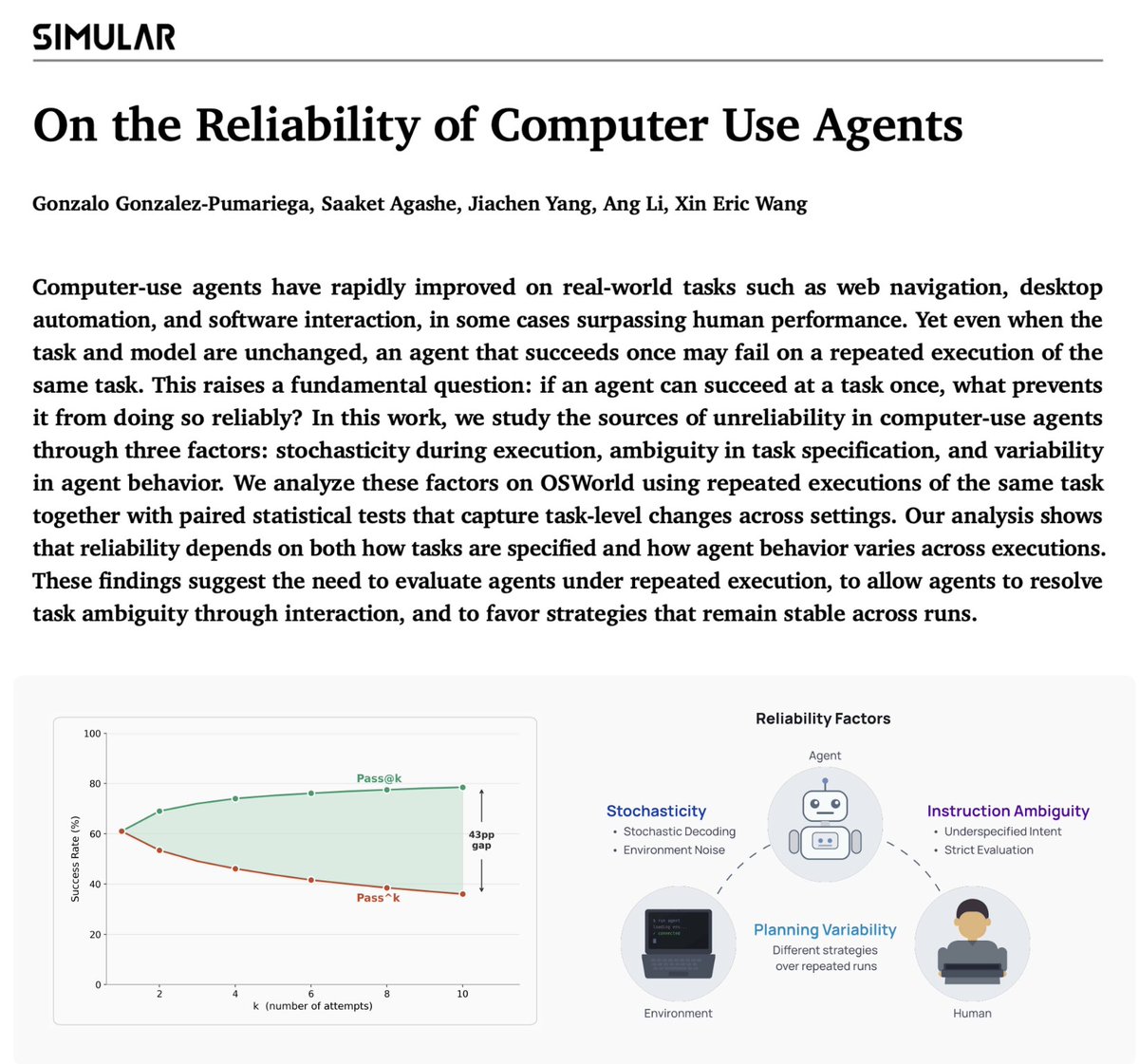
pass@k measures if it can work - that is capability. pass^k measures if it will work - this is reliability. 2025, we proved capability. achieved human-level in OSWorld as the first time. 2026, we're solving reliability. the last problem before computer use agents stop being a toy.

Computer-use agents are getting very capable. But capability is not the bottleneck anymore. 𝐑𝐞𝐥𝐢𝐚𝐛𝐢𝐥𝐢𝐭𝐲 is. Benchmarks reward “works once.” Real-world systems require “works every time.” In On the Reliability of Computer Use Agents, we study WHY this gap exists and

Today we're finally out! Something I keep coming back to: continual learning and world modeling are two sides of the same coin. Specialization starts where training ends. It's the agent continuously building its model of the world it actually lives in. That's when clever demos turn into real expertise. We're hiring! @NeoCognition
Introducing @NeoCognition, the agent lab for specialized intelligence. Everyone needs experts, but human expertise does not scale. Backed by $40M seed funding, we build self-learning agents that specialize across domains to make expertise abundant.
🔥 Finding the "ChatGPT Moment" for CUA! On April 19, WebAgentLab x @qingke Community presents the "ICLR 2026 CUA Workshop" livestream. We've gathered top pioneers from UWaterloo, HKU, Fudan, Alibaba, and Minimax to deep-dive into: 💻 Real-world deployment & multi-platform unification of GUI Agents 🚀 Autonomous continual learning in dynamic environments 🛠️ Breaking data dependency in agent infrastructure Great research belongs beyond PDFs and repos. Join us to witness the new era of AI taking over the keyboard and mouse! 🖱️ #CUA #GUIAgent #LLM #AI #ICLR2026


Galen Gao @Ninggao88
126 Followers 1K Following 🛠️ Building Linkloud and more 🔋 ex Hillhouse Capital. Supercharging founders to go global. Manifest, build and invest.
Mingdian Liu @MingdianLiu
215 Followers 1K Following Engineer at @XPENG_Global for self-driving; pre-Amazon; pre-Meta; pre-Snap; AI for Science; VLM; AI Infra
Dejia Xu @Ir1dXD
556 Followers 2K Following ✨ Research Lead @LumaLabsAI. https://t.co/bCoyXJpKDU @WNCG_UT @VITAGroupUT
David Han @David_Han66
119 Followers 719 Following AI PhD @ UC Berkeley Toward agents that produce in the real economy. The Eval comes first. Building Agents' Last Exam
Cheng Yang @ChengYANG_yc
63 Followers 394 Following PhD student at @ucsd_cse | Prev Master @Tsinghua_uni
Moises Andrade | ICLR... @mshalimay
8 Followers 153 Following MSc Economics | CS PhD @ GeorgiaTech From Rio de Janeiro, Brazil


Diana Osire @Diana_Osire
56K Followers 753 Following AI educator • tools & workflows • Exploring new AI products &Online Jobs Helping you work smarter ▶DM for collabs
Hanwen Wang @hwwang06
38 Followers 577 Following '27 Undergrad @HKUSTCSE | '25 Exchange-in @UofIllinois @siebelschool | interested in #NLProc

Junbo Niu @jbniu25
63 Followers 289 Following Ph.D. candidate @PKU1898 | ByteDance Seed | Prev works OVO-Series && MinerU 2.0/2.5/Diffusion | LLM PostTrain && Fundation Model
Haoqing Wang @haoqingeric
12 Followers 135 Following Undergrad @ BUPT, Intern @MSFTResearch Asia General Agent, Computer Use Agent, MLLM, LLM
Jinbiao Wei @Mikewei_nlp
9 Followers 40 Following Rice CS @RiceUniversity → MSCS @Yale | Building efficient agents for real-world use
CamillaHu @CamillaHu2002
0 Followers 60 Following 25Fall UTD CS Ph.D, focusing on the hallucination LLM and trustworthy LLM.
Ayhem Kahri @_AyhemKahri
16 Followers 524 Following
Kanzhi Cheng @njucckevin
56 Followers 14 Following
Christopher Settles @never_settles_
2K Followers 2K Following Building RL gyms @refresh_dev | Prev AI @Uber , CS @UofIllinois | believer in community
Peter @FeelinBluu
3K Followers 2K Following human work at scale @getslesh / was @ExathAIO @Blormmy /odf 25, engineering @uoft


kaiqian cui @CuiKaiqian64402
1 Followers 99 Following
DEVIL LUCIFER @devilxlucifer54
1 Followers 7K Following
aa a @aaa145042
3 Followers 8 Following
C0de3 @c0de3_
470 Followers 2K Following Hack Windows&Linux . Kernel Bug hunter. Pentest amateur.Pwn2own 2017. AIGC Security .
Jiarui Xu @Jiarui_X
54 Followers 739 Following undergrad @NTUsg | first intern @ropedia_ai | #humanoid in physical world
ForProduction @ForProduction
9 Followers 69 Following ForProduction | Data Scientist & MLOps. I read cutting-edge AI research so you don't have to | distilling papers into production-ready insights.
Almichael Zukof @AlmichaelZ
223 Followers 5K Following Coder, Dad, Data Science Student. Professional do-gooder, Procrastinator

zx c @vdcfkvharui
0 Followers 43 Following

Sicheng Fan @Fan_Si_cheng
6 Followers 23 Following Undergraduate & Master’s degree from Fudan University. Research interests: Computer-Use Agents. Intern @Alibaba_Qwen
Shaojie Bai @ShaojieBai1
30 Followers 435 Following Ph.D. Candidate at Zhejiang University; Guest Ph.D. at University of Copenhagen | Reinforcement Learning, Differential Privacy
Rui Ye @ruiye1129
27 Followers 44 Following PhD Candidate @ Shanghai Jiao Tong University (@sjtu1896) LLM Agents / Deep Research Agents Tongyi DeepResearch @Ali_TongyiLab / SciMaster / Muse

Jian Kang @jiank_uiuc
2K Followers 1K Following stats & data sci, comp sci @mbzuai | previously @uofr @siebelschool @ideaisailuiuc @aiatmeta modeling the interconnected world

Ahaaaa🔶BNB @Ahaaaa233
25 Followers 178 Following Web3 Native | AI Researcher ~ 探索去中心化的无限可能。 ⚡️ Building the future, one block at a time.
Rachit Tibrewal @RachitTibr1007
24 Followers 652 Following
Yuxin Zuo @zuo_yuxin
238 Followers 301 Following Research Intern @Alibaba_Qwen. Interested in RL, LLMs, AI4Science.
Ruoyu Chen @RuoyuChen20
36 Followers 178 Following Ph.D. candidate in Chinese Academy of Sciences, major in interpretable AI
djif007 @djif00794329
0 Followers 64 Following
Jessica Cataneo @thejesscat
116 Followers 942 Following Founding Team - Hark ex-Waymo | ex-Lyft Pepperdine University MBA '23
Jinzhe Tan @JinzheT
51 Followers 339 Following 🧑🎓 Doctoral Student ⚖️ Interested in AI and Law 🎓 University of Montreal 🌎 Cyberjustice Laboratory
村本章憲 - Norika... @1amageek
7K Followers 6K Following Engineer. AI, Robot, Mobile, Database, Network https://t.co/zLitYYZSwx / https://t.co/RcBigXBdcq / https://t.co/pM3hpxShZm


Jing Wu 🍄 @jingwu23
41 Followers 268 Following Ex-Intern @MSFTResearch, DPhil student @AVLOxford @UniOfOxford @St_Catz | CUA Agents, 3D Vision, Generative AI, Music and Arts
Meh. @MetaSeeker006
77 Followers 627 Following Web 3/AI Enthusiast. Engineer, Technology Strategist and Social Scientist by Design.
InnerPeace @innerpeace_wu
6 Followers 72 Following
Zhuokai Zhao @zhuokaiz
5K Followers 342 Following AI Research Scientist @Meta. Building scalable intelligence. PhD @UChicagoCS.
Vishakh Padmakumar @vishakh_pk
840 Followers 683 Following Measuring and mitigating the societal impacts of AI/LLMs @stanfordnlp @stanfordAILab Prev @allen_ai @NYUDataScience
Joachim Baumann @joabaum
826 Followers 1K Following Postdoc @StanfordNLP @StanfordAILab / Prev: @MilaNLProc @UZH_en @MPI_IS @CarnegieMellon. CompSocSci, LLMs, algorithmic fairness.

kaiqian cui @CuiKaiqian64402
1 Followers 99 Following
Yu Huang @hardenyu221
2 Followers 18 Following
Feng Wu @wufeng02
27 Followers 36 Following

Ziyu Yao @ZiyuYao
2K Followers 686 Following Asst Prof @GMUCompSci. Working on LLM reasoning/planning and mechanistic interpretability. Alum @OhioState.
Jian Kang @jiank_uiuc
2K Followers 1K Following stats & data sci, comp sci @mbzuai | previously @uofr @siebelschool @ideaisailuiuc @aiatmeta modeling the interconnected world

Jieyu Zhang @JieyuZhang20
828 Followers 732 Following PhD student @uwcse | Undergrad @IllinoisCS | Intern @allen_ai @MSFTResearch @SFResearch | Apple Scholar in AI/ML (‘24) | Vision and Language
Rotem Dror @DrorRotem
327 Followers 250 Following Asst. Prof. of Natural Language Processing @UofHaifa

Ling Yang @LingYang_PU
2K Followers 179 Following Postdoc @Princeton | Prev. PhD @PKU1898. Creator of RPG / Buffer of Thoughts / ReasonFlux / MMaDA / LatentMAS / RLAnything / OpenClaw-RL
Yinjie Wang @YinjieW2024
2K Followers 302 Following PhD @UChicago, intern @Princeton; Agentic RL/Post-training; OpenClaw-RL, RLAnything, dLLM-RL
Keyang96 @keyan_ubcse
8 Followers 19 Following
Ke Yang @EmpathYang
426 Followers 1 Following CS Ph.D. @ UIUC | BEng from THU | current intern @MSFTResearch | ex-intern @Amazon AWS
Huaxiu Yao @HuaxiuYaoML
7K Followers 593 Following Assistant Professor @unccs @uncsdss | Postdoc @StanfordAILab | Author of MetaClaw, SkillRL, ClawArena, SimpleMem, AutoResearchClaw, Agent World Model, Agent0
Yuxin Zuo @zuo_yuxin
238 Followers 301 Following Research Intern @Alibaba_Qwen. Interested in RL, LLMs, AI4Science.

Zhijie Liu @Rrocsha1793
14 Followers 145 Following I am now a graduate student studying at ShanghaiTech University.
Mauricio Velazco @mvelazco
5K Followers 2K Following Security Research @Microsoft || Purple Team || Noob
Wei Yang @davidyoung8906
331 Followers 332 Following Faculty @UT_Dallas PhD @IllinoisCS Alma Mater @sjtu1896 @武汉外国语学校 Hobby @dota2 @acmilan
Feng Sidong @FSidong
57 Followers 106 Following Assistant Professor at The Chinese University of Hong Kong, Shenzhen (CUHK-Shenzhen) @cuhksz
Yuhang He (Henry) @HenryOxplore
63 Followers 377 Following Senior Researcher at Microsoft Research, @UniofOxford,@WHU_1893,@MSFTResearch
Jing Wu 🍄 @jingwu23
41 Followers 268 Following Ex-Intern @MSFTResearch, DPhil student @AVLOxford @UniOfOxford @St_Catz | CUA Agents, 3D Vision, Generative AI, Music and Arts
Zhiqiang Shen @szq0214
743 Followers 128 Following Assistant Prof @MBZUAI. Emergency AC in ICLR26, Area Chair in ICML26 | Previous Postdoc @CarnegieMellon | Our Group: https://t.co/goRzQZV12p.
Rahul Gupta @rahul1987iit
240 Followers 322 Following Responsible AI @Amazon AGI (Nova models) | Organizer @TrustNLP | Organizer @UnlearningSEM
Arman Cohan @armancohan
3K Followers 943 Following Assistant Professor of Computer Science @Yale | Research Scientist @Ai2 | LLM/NLP/AI Research

Xiaoqing Guo @guo_xiaoqing
87 Followers 83 Following Assistant Professor in Department of Computer Science at Hong Kong Baptist University @hkbaptistu.
Ruoyu Chen @RuoyuChen20
36 Followers 178 Following Ph.D. candidate in Chinese Academy of Sciences, major in interpretable AI
Zhehao Zhang @Zhehao_Zhang123
577 Followers 793 Following 👨🍳 PhDing @osunlp | Interning @netflix📌 Prev. @SALT_NLP @amazon @adobe @MSFTResearch | 🤖Language Agent, Agent Safety, NLP&ML #NLProc

Quan_Sun @QuanSun6
22 Followers 163 Following
YuanLiuuuuuu @a33668874586
73 Followers 668 Following Researcher at WeChat AI, focusing at large multimodal model and large language model. https://t.co/eyVqwA3CzZ
Chengguang Gan @ChengguangGan
211 Followers 250 Following LLM Researcher in @techtouch_inc. Doctor https://t.co/PckwYgZSQS Opinions are my own.
Nikhil Singh @nikhilsinghmus
557 Followers 492 Following Asst Prof @DartmouthCS. Human-AI Systems (https://t.co/X8LV4tikck). Prev: PhD @MIT. @allen_ai @NetflixResearch @berkleecollege.
Danny To Eun Kim @TEKnologyy
650 Followers 2K Following PhD student @LTIatCMU working with @841io on NLP & IR | Prev: MEng @ai_ucl
Sharon Li @SharonYixuanLi
13K Followers 873 Following Associate Professor @WisconsinCS. Making AI reliable for the open world. Program Chairing #ICML2026. Prev: @Stanford @Cornell
Sean Du @xuefeng_du
2K Followers 3K Following Assistant Professor @NTUsg | Ph.D. @WisconsinCS, 30under30 @Forbes asia | reliable machine learning 🤖️ ⛑️ | Opinions are my own
Samuel (Min-Hsuan) Ye... @Samuel861025
120 Followers 100 Following CS PhD student at University of Wisconsin Madison. Advised by Prof. Sharon Li
Jiatong Li @JiatongLi0418
72 Followers 282 Following PhD Student @WisconsinCS | BS, MS @USTC | Intern @Alibaba_Cloud | trustworthy machine learning & large language models
Seongheon Park @seongheon_96
136 Followers 363 Following CS PhD Candidate @WisconsinCS | Intern @Microsoft
Changdae Oh ✈️ AC... @Changdae_Oh
391 Followers 631 Following Intern @Meta Superintelligence Labs | PhD student @ UW-Madison | Prev: @NAVER_AI_Lab, @CarnegieMellon, @USeoul

You might like



















