

Huy Hoàng Lê @Splendor1811
Joined September 2022-
Tweets2K
-
Followers17
-
Following528
-
Likes4K

All 23 lectures for my CMU Advanced NLP course are now on YouTube. The slides and 20 code examples are also publicly available. - YouTube: youtube.com/playlist?list=… - Course Page (Slides, Schedule): cmu-l3.github.io/anlp-spring202… - Code: github.com/cmu-l3/anlp-sp… The lectures are grouped into 7 themes: fundamentals, architectures, learning & inference, modeling, evaluation, RL & agents, and scaling & efficiency. Check them out if you’re looking for an introduction or refresher on the fundamentals of LLMs, key ideas from recent NLP research, or are just curious to learn more.


@prateek_0041 I have been going through the same journey. Writing notes after reading has helped me a lot. One of the introductory articles I have written - on CUDA kernels x.com/unmesh_padalka…


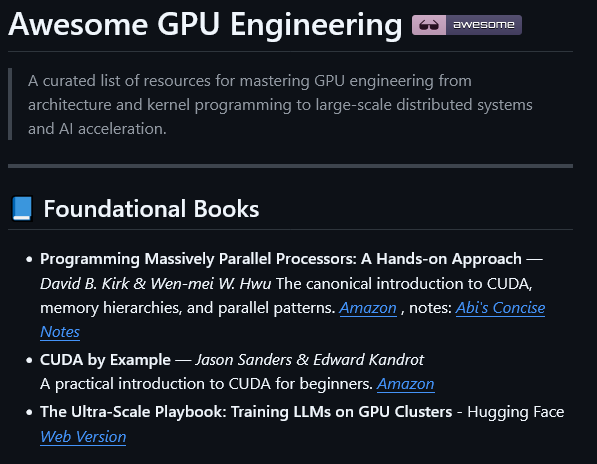
Fuck your paid courses, Master GPU engineering for AI systems. From foundational books and CUDA/ROCm programming to low-level optimization, Nsight tools, multi-GPU orchestration, distributed training and AI acceleration techniques. Excellent reference for embedded GPU work or large-scale AI infrastructure, curated collection covering: - CUDA & ROCm programming - Kernel optimization & performance tools - Multi-GPU systems & distributed training - Architecture deep dives, Triton, CUTLASS, and more A goldmine for anyone working on high-performance AI infrastructure, kernel development, or systems-level GPU work. - github.com/goabiaryan/awe…

Claude Fable 5 [max] wrote the first genuine (and fastest) megakernel ever submitted to KernelBench-Mega. It was tested on: Kimi-Linear W4A16 batch-1 decode for RTX PRO 6000 Blackwell. Every prior model "won" it with a multi-kernel Triton pipeline that fails our single-fused-kernel authenticity gate > Opus 4.8 at 14.4x > GLM-5.2 11.1x > GPT-5.5 4.3x > Sonnet 5 4.0x. Fable shipped 18.7x over reference, and torch.profiler shows exactly ONE cooperative kernel launch per decoded token. Int4 dequant (nibbles unpacked in-register, never materialized), conv+SiLU, KDA gated-delta state, MLA absorbed-latent attention with online softmax, MoE router + top-8 experts, RMSNorms, even the KV cache append all inside one launch, staged by 14 grid barriers. We overwrote its input buffers mid-audit to prove it recomputes on live data. It does. The advantage grows with context. 17.8x at 2k, 18.9x at 8k, 19.5x at 16k. Longer context means a bigger KV cache and more attention work per token which is usually where a decode kernel bleeds. Keeping everything in one launch amortizes the fixed barrier overhead and the int4 GEMV stays bandwidth-bound, so the gap over the reference widens instead of closing. It spent 64% of the session in silence timing the baseline, microbenchmarking grid barriers, deriving a ~29x bytes/token roofline, then wrote the whole kernel once, hit 14.4x on the first benchmark, and spent the last hour deleting barriers and making int4 dequant free (one LOP3 + HSUB2/HMUL2). The one regression it tried (finer split-K) it measured and reverted instead of rationalizing. kernelbench.com/mega


CMU PhD who built the kernels NVIDIA now ships in TensorRT-LLM explained fast attention in 68 minutes - better than $1200 GPU programming courses. pick the attention pattern -> generate a fused CUDA kernel -> drop it into vLLM/SGLang -> same GPU, way more tokens per second. That loop is why FlashInfer now powers inference at NVIDIA, vLLM, SGLang, and half the serving stacks you use. FlashInfer + Triton + JIT-compiled kernels + paged-KV attention - that's the stack.
Here's part 1 (of 5) of my short course on efficient LLM inference that I taught at Columbia University. Slides are heavily updated from two weeks ago. youtube.com/watch?v=3ggYI8…

This Fall at CMU we're teaching a new course on AI Agents! The goal is that you learn how to create a scaffold, build evals, and train an agentic LLM using RL. We'll try to balance theory and practice, and introduce modern frameworks and best practices.

Train your own DSpark more efficiently than DeepSpec with Speculators! We’ve already scaled it up to GLM 5.2 and you don’t need TBs of storage. Basic online training example here github.com/vllm-project/s…

And it's not locked to DeepSeek's checkpoints. 🧩 The Speculators library (github.com/vllm-project/s…) lets you train and package DSpark draft models in a standard, HF-compatible format that vLLM loads directly. Already validated on Qwen3-8B and GLM-5.2. Run it on vLLM nightly now:

Six offline RL distillation losses. One base model. The exact same math rollouts. Do they actually learn the same thing? Turns out most "new" losses — RFT, DFT, offline GRPO — write nearly the same direction in weight space as plain SFT. Only DPO learns something genuinely different: near-orthogonal, its own loss basin, rewires what the network computes. Reward-weighting changes the step size. DPO changes the direction. Accepted at @icmlconf (MechInterp workshop) paper + interactive companion 👇 huggingface.co/spaces/AlexWor…


分享一门来自加州大学伯克利分校的进阶课程:Advanced LLM Agents。 这门课聚焦大语言模型 Agent 的最新进展,从推理到规划、从代码到数学证明,系统拆解“能思考、会行动”的代理是怎么做出来的。 课程由 Dawn Song 教授主讲,并邀请 Google、Meta 等公司的研究人员担任客座讲师,内容硬核、案例前沿。 课程地址:rdi.berkeley.edu/adv-llm-agents… 你将学到: - 推理时技术与后训练:把复杂推理能力真正“训出来、用起来” - 搜索与规划:让代理更会选、更会走、更会做决策 - 代码生成与验证:打造更可靠的编程助手与自动化工具 - 数学定理证明与自动形式化:探索 AI 进入数学的关键路径 - 多模态自主代理:视觉与文本协同,完成更复杂的任务闭环 - AI 安全与安全性:面向部署的可靠性与风险控制 课程提供完整录像、PPT 与配套资料,适合具备机器学习基础的学生和开发者系统进阶。
This is very close to how the text-albumentations library works. Inputs a passage source, and generates task-oriented data from it. The variance comes from the input docs. The quality comes from the local/remote LM. The Synthetic Data Playbook HF article also talks about domain data distribution + task variance for good synthetic data. This new Autodata paper adds more review mechanics with a weak/strong resolver and an external judge, which is actually a super cool idea to maintain good dataset quality.



New blog post on harness optimization. We hit Sonnet 4.6 performance with a 7x cost improvement. Fable 5 was the first frontier model release that evaluated on legal tasks. It only scored 13%, the worst performance among all benchmarks evaluated. @Harvey released this benchmark called Legal Agent Benchmark (LAB) just a month prior. It contains a set of realistic legal matters. Each task gives the agent a closed workspace of documents (contracts, emails, spreadsheets, slide decks) and asks for a concrete deliverable: a diligence memo, an issue list, a redline, a draft. An LLM judge grades the deliverable against a long rubric containing 61 distinct binary criteria each on average. Many frontier models such as Gemini 3.1 Pro don't surpass 0% all-pass rate (all rubric criteria passed). With automatic harness optimization, we manage to push DeepSeek V4 Pro from 0% to 5% all-pass rate, achieving parity with Sonnet 4.6 for 1/7 of the price. Read the blog post for the details: huggingface.co/spaces/joelnik…
Sorting which financial docs are worth an analyst's time is surprisingly hard for frontier LLMs. With an expert-labeled dataset and on-policy distillation, Bridgewater fine-tuned a model to do it reliably and cheaply. thinkingmachines.ai/news/learning-…
Our MOPD from MiMo-V2-Flash has been widely adopted in modern post-training pipelines. Now the paper is out with more details & comparison. Check it out: arxiv.org/abs/2606.30406


Stanford dropped their latest course on Parallel Programming, GPU, and CUDA. 24 hours, 19 lessons. this is one of the hottest skills that AI labs are looking for. it covers: > GPU architecture and CUDA > performance optimization > multi-core processors and architectures watch here: youtube.com/playlist?list=…


先说结论 : 利好存储。 Dspark太猛了,它把大模型吞吐量提升了51%-400%,推理速度快了60%-85%。DeepSeek 不仅发布了 DSpark 技术,还同步开源了名为 DeepSpec 的全栈代码库。 梁圣的恩情我们这辈子是还不完了。 如果读不懂Dspark原文的朋友,可以读PyTorch核心维护者Dmytro Dzhulgakov 的解读,如果解读也读不懂,就看我下面的大白话版👇🏻👇🏻👇🏻 1.批处理解码: GPU的计算瓶颈在显存带宽,大部分时间都花在了把模型权重从显存搬到运算核心上。而解码10个token和解码1个token花费的时间时间差不多。所以就要一次性搬尽可能多的token到计算核心,榨干每一次显存搬运操作。 2.推测解码: 内容生成时,第n+1个token依赖于第n个token的结果。正常方法就是一个个来,没办法并行。论文中的方法是绕路,猜出接下来的几个token,一次性喂给模型做验证。猜的环节用小模型,验证用大模型批量验证,所以很高效。 3.草稿模型: 小模型猜测速度快,大模型验证,通过了就全收,哪里有分歧,就在哪里重来。 4.推测不免费: 草稿模型带来了额外的开销,速度太慢或者通过率低都不划算,论文给出一个核心公式以平衡速度,预测数量以达到最优化效果。 5.多token预测 用的预测小模型不是单独训的,是直接来自目标模型的最后一层,在上面加1-2层transformer头,这样会又快又准。 6.Dflash - 用并行一口气猜完 串行会慢,Dflash是在一次前向传播中,并行把n个候选位置全部猜完,速度虽然快,但是后续的位置上下文少,准确率降低了。 7.Dspark - 快和准确率都要 把串行和并行拼在一起,第一步用Dflash并行猜测,第二步串行注入前缀依赖(可以理解为上下文)进行修正,用来提升准确率。 8.马尔科夫头-更便宜 上一条中一次并行,一次串行,如果第二步注入全部上下文,那开销又上去了。论文中使用的是马尔科夫头,只看候选位置前面的1个token就可以确定修正方向。这就很节省开销了。 9.草稿长度动态调整 GPU空闲时,就多猜几个token,高并发时就少猜几个以提高准确率。 10.草稿校准 为防止大模型盲目自信,会持续观测草稿器的实际表现,边跑边调,越跑越准。 总结: 这十个概念并不算全新概念,deepseek的创新是完成了算法、调度、硬件适配三位一体的端到端工程闭环整套方案。 为什么说利好存储? 因为整个论文的逻辑就是提高了大模型的输出效率,不再是一个字一个字的往外蹦了,而是一堆一堆往外喷。 也就是大厂建的算力中心能供应更多的算力了,更能赚钱了,买高端存储也相对划算了。本来赚一块钱的,现在能赚一块6了。 现在本身就急缺算力,御三家都在降智,算力供应不上,一旦提高了效率,供应给更多用户,就可以卖更多的钱。 而且推理更快、更便宜之后,AI应用会进入更多场景,调用量、并发量和Agent运行时长都可能大幅上升。只要新增需求超过效率提升,GPU和HBM总需求就不会下降,反而会继续增加。 本身犹豫的基建投资,现在也会变得更加果断。 当然凡事有个头,算力供应总有过剩的时候。但我觉得还早,现在深度使用AI的用户还不到全人类1%,就这样而言算力已经不够用,未来ai会渗透到各种生活场景,每个人都会主动或者被动的深度使用AI。所需要的算力是现在的百倍千倍。 所以Spark的出现,将是存储的需求放大器。


DSpark from @deepseek_ai ingeniously integrates many speculative decoding ideas to achieve 1.5x to 5x higher throughput in a real production system Let's understand it with 10 ideas, starting from the very basics 🧵



Software is evolving, so should you! These are the best blogs I read to understand GPUs and CUDA!

GitHub 开源 CUDA 系统教程:LeetCUDA(从入门到进阶,一站打通) 200+ 个循序渐进的 CUDA Kernel 实战题,配套 HGEMM 库性能可达 cuBLAS 的 98%~100%。另有 100+ 篇高性能计算技术博客,专讲关键技巧与优化方法,帮你从“能写”进阶到“写得又快又稳”。 GitHub: github.com/xlite-dev/Leet… 面向初学者精心设计,结合 PyTorch 梳理清晰路线:写对 → 写快 → 逼近库级性能。 适合系统掌握 CUDA 的开发者,也适合作为大模型推理优化的 AI 工程师参考与进阶路径。


NOT ELON @NOYELONvm
32 Followers 3K Following Ceo-SpaceX🚀, Tesla🚘 Founder-The Boring Company🛣 Co-founder-Neuralink, OpenAl🤖
NHẬT MINH NGUYỄN @nhmingnguyen
0 Followers 32 Following
wen👩🏻💻 @ds_wen_
25K Followers 13K Following 👋 senior data scientist. i do = data science + ai + lifelong learning with a growth mindset

🚀 @ceomusk_ai1
105 Followers 1K Following 🚀 | Spacex - CEO & CTO 🚘 | Tesla -CEO And Product Architect 🗺 | X- CEO 🚅 | Hyperloop - Founder
nana🦄 @ds_nana_
32K Followers 11K Following data scientist from a non tech background. code with coffee. share my learnings here #datascience #python #rstats #sql
Do Xuan Long @dxlong2000
216 Followers 463 Following Student Researcher @Google & CS PhD @NUSingapore | Prev. @amazon, @NTUsg
Lina Sei @shuyu621
46 Followers 476 Following web3会投研的韭菜知心姐姐| Aleo布道者| 品牌IP运营 | 有鱼有饭社区发起人|油管&视频号&抖音博主“大鱼谈链爱”|OKX是全球领先的加密货币交易平台,提供币币、合约、理财等衍生品交易服务,立即注册https://t.co/ilqOGbRGTj Social media influencer crypto trader
Corrado Ferrara @CorradoPapers
39 Followers 289 Following After a fail, I give only 1 chance, then I mute/block Surround yourself with competent, smart people and you will thrive. Stupids will bring you down with them
AI Tools Network @aitoolsnetwork
350 Followers 4K Following an online hub to find the the best AI tools
jessica🩶 @ds_jessica_
14K Followers 13K Following analytics lead & angel investor & advisor. always learning = business & innovation. doing #datascience
Co5 Workspaces @co5workspaces
561 Followers 2K Following 🏢 Co-Working Spaces 🚀 Dedicated Desks & Private Cabins 🕒 24/7 Access | Affordable Pricing 📍 Gurugram 📞 Call: 9654366845 Plot No. 25B, Institutional Area, S
fafa.👩🏻💻 @ds_fafa_
29K Followers 10K Following Data Maven with a Dash of Espresso ☕️ | Turning Numbers into Narratives | Senior Customer Insights Director | Tweets fueled by caffeine and curiosity
Duran Ocak Yusuf @duran_ocak89289
82 Followers 1K Following Deputy managing director finance of Halkbank Turkey.


Mathieu Ravaut @MatRavox
422 Followers 2K Following ML, NLP, Quant research. Graduate from @ntunlpsg | @AstarI2r | @uoftcompsci | @centralesupelec. Currently QR at ADIA.
Alex Smola @smolix
21K Followers 119 Following LLMs for interaction at https://t.co/uY2XbWTgaT, AutoML at https://t.co/xqkK2q7L02, learn ML with https://t.co/9W8dBWESkW.
Tinker @tinkerapi
12K Followers 1 Following I tink, therefore I am. Post-training API by @thinkymachines

Ning Ding @stingning
7K Followers 401 Following Researcher of AI. Assistant Professor @Tsinghua_Uni. Working on scalable methods of language and physical models.
Abheesht Sharma @penstrokes75
2K Followers 2K Following ML, LLMs, RL, RecSys @Google | Cricket fanatic | Bursts of random poetry | Prev. Applied Science @AmazonScience
lynnette ng @quarbby
2K Followers 2K Following exploring creativity / Societal Computing PhD from @SCSatCMU / IG: Littlebabypenguin / Bot Book: https://t.co/455VxhQI8S
Adithya S K @adithya_s_k
14K Followers 2K Following Scaling RL @huggingface 🤗 • Founded @cognitivelab_ai Prev : Research @MSFTResearch • ML @apple • AI Resident @lossfunk • 22
Chinmay @ChinmayKak
4K Followers 2K Following 21. gradient ascender. prev RL @MSFTResearch . love @teamIvLabs. dms open!


Yiping Wang @ypwang61
2K Followers 1K Following Prev. @xai (coding), Ph.D. @uwcse interned @MSFTResearch, undergraduate @ZJU_China. I'm interested in mathematics, agi, and physics.

Niels Rogge @NielsRogge
21K Followers 735 Following ML Engineer @huggingface. Building https://t.co/z4nyO4pjVE. @KU_Leuven grad. General interest in machine & deep learning. Making AI more accessible for everyone!
Xiuyu Li @sheriyuo
12K Followers 2K Following Post-train @StepFun_ai | Prev @RUC1937 | Opinions are my own
Chao Ma @ickma2311
3K Followers 74 Following Applied Math × AI × Chip Architectures Exploring the foundations behind modern intelligence systems. Sharing clear technical insights & visual explanations.
Li Jiang @louieworth
270 Followers 689 Following RL learner. Ph.D at @DesautelsMcGill @Mila_Quebec, previous @Tsinghua_Uni.
Yiheng Shu @YihengShu
2K Followers 1K Following PhD student @osunlp | Intern @Google | Previously @NanjingUnivers1 | Former Intern @MSFTResearch @Intuit

Kimi Developers @KimiDevs
60K Followers 1 Following The official Kimi account for developers building with Kimi Code and the Kimi API.
Dwarkesh Patel @dwarkesh_sp
240K Followers 1K Following Host of @dwarkeshpodcast https://t.co/3SXlu7fy6N https://t.co/4DPAxODFYi https://t.co/hQfIWdM1Un
Jiao Wenxiang @WenxiangJiao
948 Followers 439 Following Xiaohongshu Inc. Prev: Tencent AI Lab @TencentGlobal, PhD CUHK @CUHKofficial #LLM #Agents #Personality
Sergio Paniego @SergioPaniego
4K Followers 2K Following Machine Learning Engineer @huggingface 🤗 AI PhD. Technology enables us to be more human. 🏳️🌈
Skyler Miao @SkylerMiao7
16K Followers 307 Following Head of Engineering @MiniMax_AI Building MiniMax M3.x, Code, Audio and @Hailuo_AI

Chenyang Lyu @Chenyang_Lyu
1K Followers 839 Following Staff Researcher/Tech Lead @AlibabaGroup. Previously @MBZUAI @TencentGlobal @ml_labs_irl @IBMResearch. Working on Multilingual/Speech/Omni LLMs & Agent system.

Liam Liang Ding @liangdingNLP
851 Followers 2K Following building agentic ai @AlibabaGroup & ex-@AIstartup @JD_Corporate @TencentGlobal @Sydney_Uni. opinions are my own.



levi @levidiamode
5K Followers 708 Following 365 days of GPU programming ▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓░░░░░░░░░░░░░░░░░░ 180/365
Kevin Gu @kevingu
5K Followers 360 Following CTO @dexbythirdlayer // prev research @jumptrading, @meta, @mitibmlab, @harvard math
Mustafa Suleyman @mustafasuleyman
707K Followers 496 Following CEO, @MicrosoftAI | Author: The Coming Wave | Past: Co-founder, @InflectionAI & @GoogleDeepMind


Sigrid Jin 🌈🙏 @realsigridjin
15K Followers 1K Following experiencing context rot @ubc 🇨🇦 🇰🇷 proudly korean-canadian
Cheng Lou @_chenglou
69K Followers 460 Following Worked on: @reactjs, @messenger, @reasonml, @rescriptlang Currently: @midjourney, Pretext
λux @novasarc01
22K Followers 3K Following tensor shepherd in a non-euclidean pasture | grazing on cuda cores

Percy Liang @percyliang
109K Followers 425 Following professor of computer science @Stanford @stanfordnlp, co-founder of @togethercompute, creator of https://t.co/7R5THVogW2, co-founder of @simile_ai, pianist
Vivian Liu @viv_lavida
2K Followers 279 Following CS PhD student @Columbia. previously @GoogleDeepmind, @AdobeResearch @ADSKResearch 🌷
Jackmin @🇰🇷ICML... @jackminong
2K Followers 951 Following On a little excursion. Waku Waku! On sabbatical @PrimeIntellect 🇺🇸 Previously @JinaAI_ 🇩🇪 @MoneyLion 🇲🇾

Ethan He @EthanHe_42
38K Followers 707 Following ex world model lead @xAI | ex @Nvidia @Meta | 30+ papers, 9k citations | talk about AI, LLM, video generation, multimodal, AGI
Tengyu Ma @tengyuma
44K Followers 577 Following Assistant prof. @ Stanford; Chief AI Scientist @ MongoDB; Former Co-founder/CEO of Voyage AI Working on ML, DL, RL, LLMs, and their theory.
John Schulman @johnschulman2
77K Followers 2K Following Recently started @thinkymachines. Interested in reinforcement learning, alignment, birds, jazz music
Tony Kipkemboi @tonykipkemboi
6K Followers 2K Following enterprise ai agents // building https://t.co/Vzrm261P3N & https://t.co/msaSfPCwhs // ex. @crewaiinc, @streamlit (acq. by @snowflake), @bloomberg, @USArmy
Tanishq Kumar @tanishqkumar07
5K Followers 82 Following CS PhD student @StanfordAILab. prev math undergrad @Harvard.
Atharva @AtharvaXDevs
6K Followers 2K Following GSoC'26 @OpenScienceLabs • Backend & Devops • Dm for collab/promo • 🕉️
AVB @neural_avb
12K Followers 339 Following Neural Breakdown on YT | Read research with AI: https://t.co/Ef6m4nUpcZ | Latest vid: RLMs, Post Training | Next: Reasoning SLMYou might like



















